
By Frank Wessels
Introduction
While MD5 hashing is no longer a good choice when considering a hash function, it is still being used in a great variety of applications. As such any performance improvements that can be made to the MD5 hashing speed are worth considering.
Due to recent improvements in SIMD processing (AVX2 and especially AVX512) we are providing a Go md5-simd package that accelerates MD5 hashing in aggregate by up to 400% on AVX2 and up to 800% on AVX512.
This performance boost is achieved by running either 8 (AVX2) or 16 (AVX512) independent MD5 sums in parallel on a single CPU core.
It is important to understand that md5-simd does not speed up an individual MD5 hash sum. Rather it allows multiple independent MD5 sums to be computed in parallel on the same CPU core, thereby making more efficient usage of the computing resources.
Performance
The following chart compares the performance between crypto/md5 vs the AVX2 vs the AVX512 code:
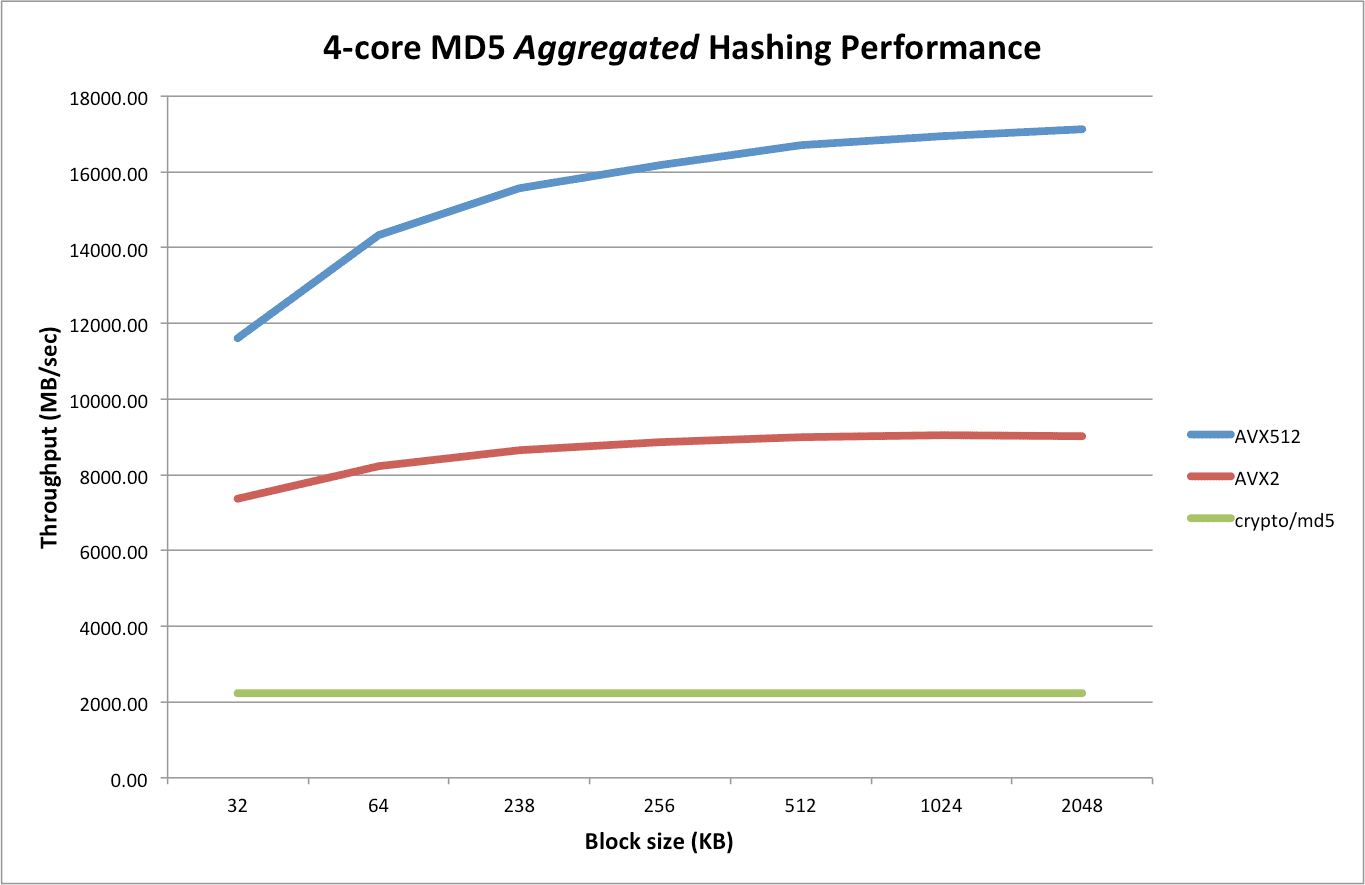
Compared to crypto/md5, the AVX2 version is up to 4x faster:
$ benchcmp crypto-md5.txt avx2.txt benchmark old MB/s new MB/s speedup BenchmarkParallel/32KB-4 2229.22 7370.50 3.31x BenchmarkParallel/64KB-4 2233.61 8248.46 3.69x BenchmarkParallel/128KB-4 2235.43 8660.74 3.87x BenchmarkParallel/256KB-4 2236.39 8863.87 3.96x BenchmarkParallel/512KB-4 2238.05 8985.39 4.01x BenchmarkParallel/1MB-4 2233.56 9042.62 4.05x BenchmarkParallel/2MB-4 2224.11 9014.46 4.05x BenchmarkParallel/4MB-4 2199.78 8993.61 4.09x BenchmarkParallel/8MB-4 2182.48 8748.22 4.01x Compared to crypto/md5, the AVX512 is up to 8x faster:
$ benchcmp crypto-md5.txt avx512.txt benchmark old MB/s new MB/s speedup BenchmarkParallel/32KB-4 2229.22 11605.78 5.21x BenchmarkParallel/64KB-4 2233.61 14329.65 6.42x BenchmarkParallel/128KB-4 2235.43 16166.39 7.23x BenchmarkParallel/256KB-4 2236.39 15570.09 6.96x BenchmarkParallel/512KB-4 2238.05 16705.83 7.46x BenchmarkParallel/1MB-4 2233.56 16941.95 7.59x BenchmarkParallel/2MB-4 2224.11 17136.01 7.70x BenchmarkParallel/4MB-4 2199.78 17218.61 7.83x BenchmarkParallel/8MB-4 2182.48 17252.88 7.91x Design
md5-simd has both an AVX2 (8-lane parallel) and an AVX512 (16-lane parallel version) algorithm to accelerate the computation with the following function definitions:
//go:noescape func block8(state *uint32, base uintptr, bufs *int32, cache *byte, n int) //go:noescape func block16(state *uint32, ptrs *int64, mask uint64, n int) The AVX2 version is based on the md5vec repository and is essentially unchanged except for minor (cosmetic) changes.
The AVX512 version is derived from the AVX2 version but adds some further optimizations and simplifications.
Caching in upper ZMM registers
The AVX2 version passes in a cache8 block of memory (about 0.5 KB) for temporary storage of intermediate results during ROUND1 which are subsequently used during ROUND2 through to ROUND4.
Since AVX512 has double the amount of registers (32 ZMM registers as compared to 16 YMM registers), it is possible to use the upper 16 ZMM registers for keeping the intermediate states on the CPU. As such, there is no need to pass in a corresponding cache16 into the AVX512 block function.
Direct loading using 64-bit pointers
The AVX2 uses the VPGATHERDD instruction (for YMM) to do a parallel load of 8 lanes using (8 independent) 32-bit offets. Since there is no control over how the 8 slices that are passed into the (Go) blockMd5 function are laid out into memory, it is not possible to derive a “base” address and corresponding offsets (all within 32-bits) for all 8 slices.
As such the AVX2 version uses an interim buffer to collect the byte slices to be hashed from all 8 inut slices and passed this buffer along with (fixed) 32-bit offsets into the assembly code.
For the AVX512 version this interim buffer is not needed since the AVX512 code uses a pair of VPGATHERQD instructions to directly dereference 64-bit pointers (from a base register address that is initialized to zero).
Note that two load (gather) instructions are needed because the AVX512 version processes 16-lanes in parallel, requiring 16 times 64-bit = 1024 bits in total to be loaded. A simple VALIGND and VPORD are subsequently used to merge the lower and upper halves together into a single ZMM register (that contains 16 lanes of 32-bit DWORDS).
Masking support
Due to the fact that pointers are directly passed in from the Go slices, we need to protect against NULL pointers. For this a 16-bit mask is passed in the AVX512 assembly code which is used during the VPGATHERQD instructions to mask out lanes that could otherwise result in segment violations.
Operation
To make operation as easy as possible there is a “Server” which coordinates individual hash states and updates them as new data comes in. This can be visualized as follows:
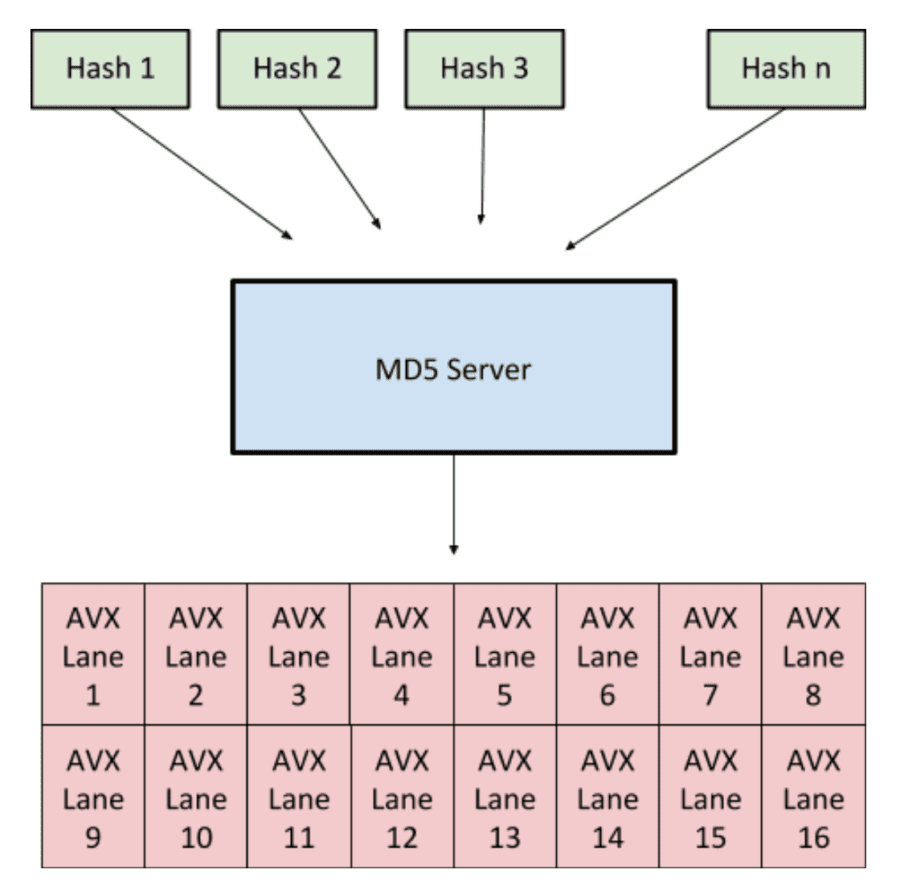
Whenever there is data available the server will collect data for up to 16 hashes and process all 16 lanes in parallel. This means that if 16 hashes have data available all lanes will be filled. However since that may not be the case, the server will fill less lanes and do a round anyway. Lanes can also be partially filled.
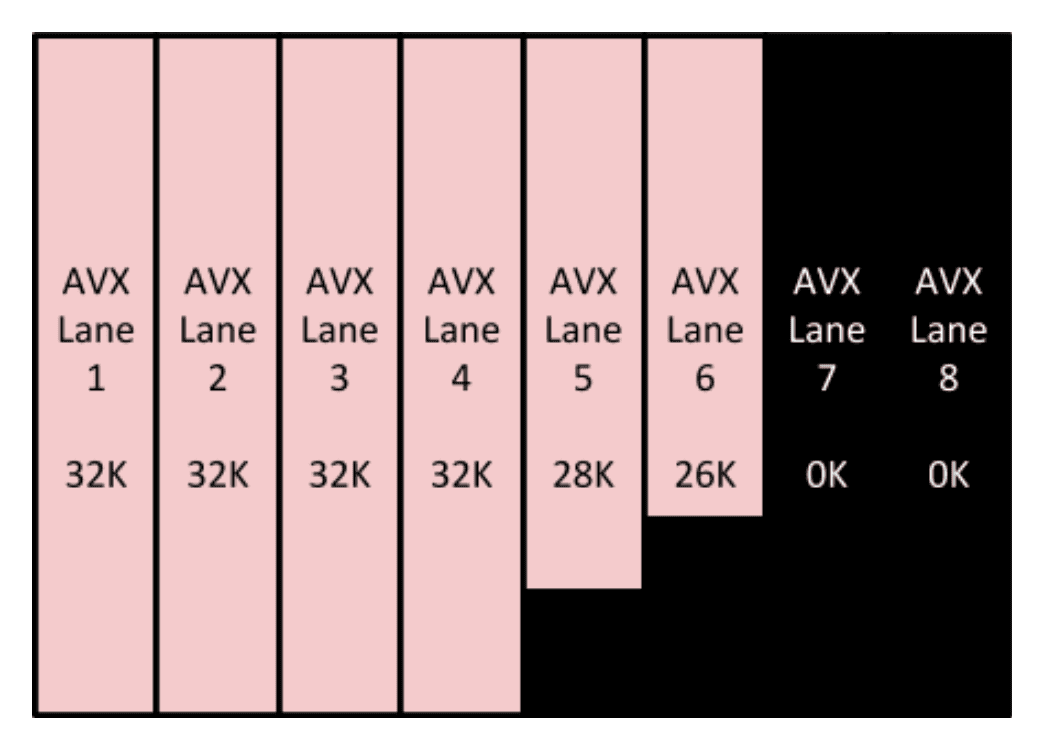
In this (simplified) example above 4 lanes are fully filled and 2 lanes are partially filled and the last 2 lanes are empty. The black areas will simply be masked out from the results and ignored (note that the actual implementation uses 16 lanes per server).
Open Source
The source code is open sourced under an MIT license and is available on github in the repository md5-simd. Give it a spin and we welcome any feedback.
{kind=link}