

A few days ago I found out that there had appeared lda2vec (by Chris Moody) – a hybrid algorithm combining best ideas from well-known LDA (Latent Dirichlet Allocation) topic modeling algorithm and from a bit less well-known tool for language modeling named word2vec.
And now I’m going to tell you a tale about lda2vec and my attempts to try it and compare with simple LDA implementation (I used gensim package for this). So, once upon a time…
What is cool about it?
Contemplations about lda2vec

Lda2vec absorbed the idea of “globality” from LDA. It means that LDA is able to create document (and topic) representations that are not so flexible but mostly interpretable to humans. Also, LDA treats a set of documents as a set of documents, whereas word2vec works with a set of documents as with a very long text string.
So, lda2vec took the idea of “locality” from word2vec, because it is local in the way that it is able to create vector representations of words (aka word embeddings) on small text intervals (aka windows).
Word2vec predicts words locally. It means that given one word it can predict the following word. At the same time LDA predicts globally: LDA predicts a word regarding global context (i.e. all set of documents).

Typical word2vec vector looks like dense vector filled with real numbers, while LDA vector is sparse vector of probabilities. When I speak about sparsity, I mean that most values in that vector are equal to zero.
Due to the sparsity (but not only) LDA model can be relatively easy interpreted by a human being, but it is inflexible. On the contrary (surprise!), dense word2vec vector is not human-interpretable, but very flexible (has more degrees of freedom).
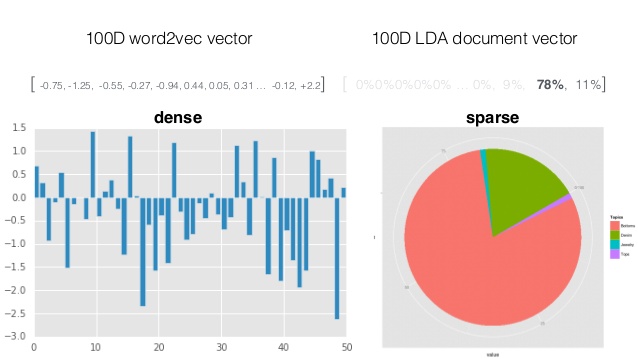
The question is: how to combine these two incombinable approaches?
The author of lda2vec applies an approach almost similar to the approach from paragraph2vec (aka doc2vec), when every word-vector sums to that word’s document label.
In lda2vec, however, word2vec vectors sum to sparse “LDA-vectors”. Then, algorithm appends categorical features to these summed word+LDA vectors and estimates a multinomial mixture over the latent word topics. The resulting vector is applied to a conditional probability model to predict the final topic assignments for some set of pre-defined groupings of input documents.
Thus, when we speak about predicting words in text, we can predict the following word not only given the context of that word, like:
P(Vout|Vin)
but also considering probability of two words co-occur in certain topic and with certain categorical features, like:
P(Vout|Vin+Vdoc+Vfeature)
where
Vdoc – is sparse LDA vector
Vfeature – some categorical feature (say, zip-code)
Applying this approach to practice, it might be possible to make supervised learning models if we get very good resulting topics. We can try to use lda2vec for, say, book analysis. For every word, lda2vec sums this word’s word2vec vector to LDA-vector and then adds some known categorical features (like year or book publisher’s name). Then, lda2vec uses the resulting vector to assign the resulting LDA topics to the respective authors of the books. What’s interesting, the resulting vectors may be used to predict some author-specific parameters, like each author’s popularity.
In a nutshell

For those of you, who doesn’t like long stories, I can concentrate all the above information into several bullets.
So, what is it all about?
- Word2vec models word-to-word relationships, while LDA models document-to-word relationships.
- Lda2vec model attempts to combine the best parts of word2vec and LDA into a single framework.
- Lda2vec model is aimed to build both word and document topics and make them interpretable, with an ambition to make supervised topics over clients, times, documents etc.
And why someone should need it?
- lda2vec approach should improve quality of topic modeling
- Business should like this approach, because they can, say, better typify their customers (for example, this customer is 60% sporty and 40% drunkard) based on the customers’ comments and different meta-information (like zip-codes, countries ets.)
Comparing Lda2vec to LDA in terms of topic modeling
Dataset
The author uses “Twenty newsgroups” sample dataset from scikit-learn python ML library (i.e. sklearn.datasets) for demonstrating the results. This dataset consists of 18000 texts from 20 different topics. All the data is split into “train” and “test” datasets. For lda2vec example the author uses the training part of the dataset.
The actual topics are as follows:
- comp.graphics
- comp.os.ms-windows.misc
- comp.sys.ibm.pc.hardware
- comp.sys.mac.hardware
- comp.windows.x
- rec.autos
- rec.motorcycles
- rec.sport.baseball
- rec.sport.hockey
- sci.crypt
- sci.electronics
- sci.med
- sci.space
- misc.forsale
- talk.politics.misc
- talk.politics.guns
- talk.politics.mideast
- talk.religion.misc
- alt.atheism
- soc.religion.christian
Their names are not too human-readable, but it is possible to understand what these topics are about.
Now, let’s compare the topics lda2vec produces with topics from the pure LDA algorithm (I used gensim package for this).
Evaluation criteria
I evaluated the results of lda2vec and LDA using two subjective criteria (sorry, I was too lazy to do something more objective):
- Number of real topics I am able to assign to the lda2vec (or LDA) topics at the first glance. I will write the assigned real topics in brackets, like (sci.med).
- Number of lda2vec (or LDA) topics that look OK. I mean topics, which look reasonable for me even if I’m unable to assign any real topic to them. I will tag such topics with (looks ok) tags.
Comparison
The author shows the following output of his lda2vec implementation in his GitHub r…:
- topic 0 out_of_vocabulary hicnet x/ oname hiv pts lds eof_not_ok
- topic 1 out_of_vocabulary hiv vitamin infections candida foods infection dyer diet patients (sci.med) (looks ok)
- topic 2 out_of_vocabulary duo adb c650 centris lciii motherboard fpu vram simm (looks ok)
- topic 3 yeast candida judas infections vitamin foods scholars greek tyre
- topic 4 jupiter lebanese lebanon karabakh israeli israelis comet roby hezbollah hernlem (talk.politics.mideast) (looks ok)
- topic 5 xfree86 printer speedstar font jpeg imake deskjet pov fonts borland (looks ok)
- topic 6 nubus 040 scsi-1 scsi-2 pds israelis 68040 lebanese powerpc livesey
- topic 7 colormap cursor xterm handler pixmap gcc xlib openwindows font expose (comp.graphics) (looks ok)
- topic 8 out_of_vocabulary circuits magellan voltage outlet circuit grounding algorithm algorithms polygon
- topic 9 amp alomar scsi-1 scsi-2 68040 mhz connectors hz wiring (looks ok)
- topic 10 astronomical astronomy telescope larson jpl satellites aerospace visualization redesign (sci.space) (looks ok)
- topic 11 homicides homicide handgun ># firearms cramer guns minorities gun rushdie (talk.politics.guns) (looks ok)
- topic 12 out_of_vocabulary koresh adl bullock atf batf fbi davidians waco nra
- topic 13 stephanopoulos stimulus keenan vat prize lopez gainey
- topic 14 bike dod# lyme :> corn gt behanna cview bmw bikes (rec.motorcycles) (looks ok)
- topic 15 out_of_vocabulary algorithm 80-bit ciphers cipher plaintext encrypted escrow ciphertext decrypt (sci.crypt) (looks ok)
- topic 16 riders bike rider jody satan eternal helmet riding god ra
- topic 17 stephanopoulos sumgait secretary karina q senator serbs azerbaijani (talk.politics.misc) (looks ok)
- topic 18 out_of_vocabulary tires anonymity tire brake plaintext ciphertext ciphers helmet
- topic 19 m”`@(“`@(“`@(“`@(“`@(“`@(“`@(“`@(“` max>’ax>’ax>’ax>’ax>’ax>’ax>’ax>’ax pts pt det 55.0 $ tor nyi
Although the topics look dirty enough, it is possible to label some of them with real topic names. Personally I was able to assign 8 real topics to the lda2vec topics and 11 of them look ok (including those I was able to label).
And now let’s compare this results to the results of pure gensim LDA algorihm. I sketched out a simple script based on gensim LDA implementation, which conducts almost the same preprocessing and almost the same number of iterations as the lda2vec example does. You may look up the code on my GitHub account and freely use it for your purposes.
So, the LDA topics are the followng:
-
- topic 0: game team play player win season last hockey score run (rec.sport.hockey) (looks ok)
- topic 1: nasa gov jpl nec dseg power run center cool research
- topic 2: government war tax insurance cramer arm law militia health bear
- topic 3: armenian turkish law muslim jew greek turk government armenia jewish (talk.politics.mideast) (looks ok)
- topic 4: believe christian mean science exist bible truth reason book belief (alt.atheism) (looks ok)
- topic 5: drive washington mail mac space please hard thank computer disk
- topic 6: file run thank version mit mouse help card graphic ibm (looks ok)
- topic 7: key encryption clipper government phone public chip netcom clinton information (sci.crypt) (looks ok)
- topic 8: jesu christian believe life day tell live law love christ (soc.religion.christian) (looks ok)
- topic 9: scsi drive bit card ide mac file color controller bus (comp.sys.mac.hardware) (looks ok)
- topic 10: pitt food bank msg gordon keith water cause geb caltech
- topic 11: car drive buy dealer israeli navy price mile virginia really
- topic 12: thank drive usa cleveland please sale mail cwru computer monitor
- topic 13: max uiuc value manager nasa cso men show set number
- topic 14: space bike nasa list ride launch orbit motorcycle image data
- topic 15: price sale file org access uucp help bob net maynard
- topic 16: key chip clipper bit encryption law government technology toronto alaska (looks ok)
- topic 17: gun israel israeli arab kill weapon firearm attack american control (talk.politics.guns) (looks ok)
- topic 18: van chi uchicago win helmet princeton access det rutger tor
- topic 19: jim government drug never isc udel fbi cwru case morality(talk.politics.misc) (looks ok)
You may see that LDA shows almost similar results: I was able to label 8 topics and 11 of them look normal for me.
Thus, I assume current lda2vec implementation to produce good output, but it is not significantly better than the output of pure LDA (however, the results of both LDA and lda2vec may be even better if we increase the number of iterations).
Disclaimer: someone may say that the number of assigned topics as well as the number of looking-ok topics is lower (or higher), but nevertheless it is obvious that the quality of topic modeling for both tools is almost the same.
How to try it myself?
Installing lda2vec
Ok, how do I shot web?
You may easily download the lda2vec implementation from its author’s GitHub repository, then extract the archive into some directory, then use Linux command shell to install the lda2vec via setup.ru:
sudo python /path–to–lda2vec–package/lda2vec/setup.py install
where /path-to-lda2vec-package/ - is obviously the path to the unzipped lda2vec.If you install the archive into non-standard directory (I mean that directory with all the python libraries), you will need to add the path to the lda2vec directory in sys.path. It’ll be like:
import sys
sys.path.append(‘/home/torselllo/lda2vec/’)print sys.path>>[‘/usr/lib/python2.7’, ‘/usr/local/lib/python2.7/dist-packages’,‘/usr/lib/python2.7/dist-packages’, ‘/usr/lib/pymodules/python2.7’,‘/home/torselllo/lda2vec/’]
And it’s done. You may now try the tool. But do not forget about the dependencies!
Installing the dependencies
You need to install the following dependencies:
- NumPy – the fundamental package for scientific computing with Python. It is really fundamental. One of the most fundamentall python packages.
- Chainer – a powerful, flexible, and intuitive framework of neural networks (according to the official slogan, not my opinion).
- spaCy – a library for industrial-strength text processing in Python (also the definition from the official website)
The most obvious way to install all the above mentioned dependencies is pip.
Facing possible troubles with spaCy
It is worth noting that spaCy may not be an easy thing to install. For example, after installing it with pip, you may try to start lda2vec immediately after the installation. But you’ll get the following input-output error:
>> IOError: /usr/local/lib/python2.7/dist–packages/spacy/en/data/vocab/strings.json.
If you try to find the cause of such error, you will see that there is really nothing exists in that path. Then you will probably consult official spaCy website and see that you need to install the model for English language using the following shell command:
sudo python –m spacy.en.download
Be advised that the size of the model is 519.05MB.
It looks easy but not that obvious if you just install spaCy as the dependency without visiting the official website.
Your problems may continue if the model for English language will download into wrong directory (yes, it may happen). For example, it may download into:
/usr/local/lib/python2.7/dist-packages/spacy/data/en_default-1.0.7,
while lda2vec will continue looking for the model in
/usr/local/lib/python2.7/dist-packages/spacy/en/data/
To end this story up, you may simply use the dirty hack. I mean that you can just move the model into the required directory with the mv shell command. I did it like this:
sudo mv /usr/local/lib/python2.7/dist–packages/spacy/data/en_default–1.0.7 /usr/local/lib/python2.7/dist–packages/spacy/en/data/
Now it works! And you may try the word2vec example. But remember that you need to be patient if you do not do GPU computations (which are said to be 10x times faster). In a version of lda2vec I used (as of January, 30 2016), it took me more an hour to process just 500 input documents on a machine with core i5 2 MHz processor and 2 Gb RAM.
Conclusion
This was a tale about the interesting approach to topic modeling named lda2vec and my attempts to try it and compare it to the simple LDA topic modeling algorithm.
Personally I find lda2vec intriguing, though not very impressive at the moment (The moment is January, 30 2016, by the way).
{kind=link}