
Arthur C. Clarke famously stated that “any sufficiently advanced technology is indistinguishable from magic.” No current technology embodies this statement more than neural networks and deep learning. And like any good magic it not only dazzles and inspires but also puts fear into people’s hearts. This primer sheds some light on how neural networks work, hopefully adding to the wonder while reducing the fear.
One known property of artificial neural networks (ANNs) is that they are universal function approximators. This means that any mathematical function can be represented by a neural network. Let’s see how this works.
Function Approximation
Universal function approximation may sound like a powerful spell recently discovered. In fact, function approximation has been around for centuries. Common techniques include the Taylor series and the Fourier series approximations. Recall that given enough terms, a Taylor series can approximate any function to a certain level of precision about a given point, while a Fourier series can approximate any periodic function. By definition, these series are linear combinations of multiple terms. The same is true of neural networks, where output values are linear combinations of their input. The difference is that neural networks can approximate a function over a set of points.
To illustrate, consider the function  . This function describes a saddle, as shown in Figure 1. This function is clearly nonlinear and cannot be accurately approximated by a plane (such as a linear regression). Can NNs do better?
. This function describes a saddle, as shown in Figure 1. This function is clearly nonlinear and cannot be accurately approximated by a plane (such as a linear regression). Can NNs do better?
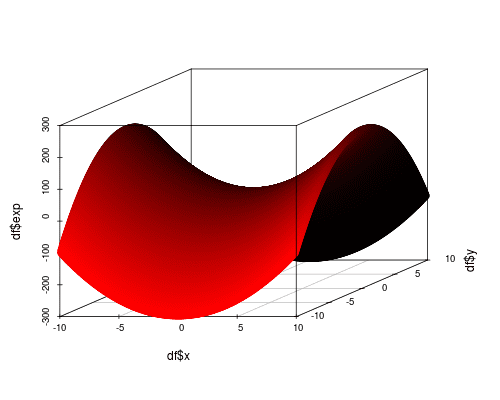
Figure 1. The saddle function 2x^2 – 3y^2 + 1.
For sake of argument, let’s attempt to approximate this function with a  network anyway. In its most basic form, a one layer neural network with $latex $n input nodes and one output node is described by
network anyway. In its most basic form, a one layer neural network with $latex $n input nodes and one output node is described by  , where
, where  is the input,
is the input,  is the bias and
is the bias and  is the weight matrix. In this case, since
is the weight matrix. In this case, since  is a scalar, is simply a vector. In Torch, this network can be described by
is a scalar, is simply a vector. In Torch, this network can be described by
require "nn"model = nn.Sequential()model:add(nn.Linear(2,1))
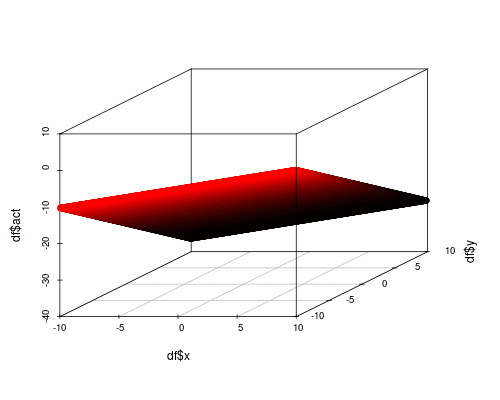
After training, we can apply the training set to the model to see what the neural network thinks  looks like. Not surprisingly it’s a plane, which is far from what we want.
looks like. Not surprisingly it’s a plane, which is far from what we want.
Let’s bring in the cavalry and add a hidden layer to create a  network. Surely with a hidden layer (and more parameters) the network can do a better job of approximating . In Lua, we say
network. Surely with a hidden layer (and more parameters) the network can do a better job of approximating . In Lua, we say
require "nn"model = nn.Sequential()model:add(nn.Linear(2,10))
model:add(nn.Linear(10,1))
Alas, it isn’t so. The result is still a plane, albeit slightly rotated.
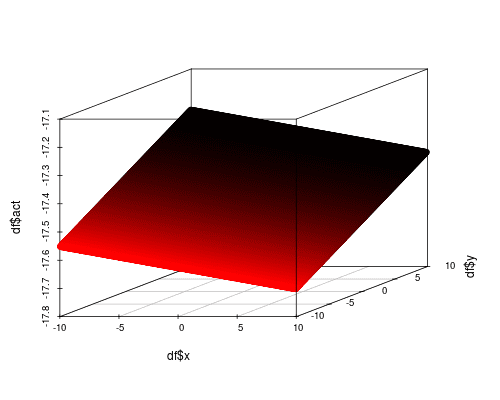
Before you lose faith in artificial neural networks, let’s understand what’s happening. In the single layer network with one output node, we said was a vector. In this case is a proper matrix since the output is a hidden layer with 10 nodes. So is a vector of size 10. In the output layer we have a new weight matrix and bias term applied to . Mathematically, the second layer is simply applying a second linear transformation. In others words, we still get a plane, since all terms are linear! To move beyond linear functions, we need to inject nonlinearity in the model.
Activation Functions
Linearity is an exceptionally useful property, but in terms of functions, it’s not particularly interesting. The nonlinear world is far more mysterious and exciting, and so it is with neural networks. Nonlinearity is injected into neural networks through the use of an activation (aka transfer) function. This function  is applied to the linear component:
is applied to the linear component: ") . The choice for ranges from the sigmoid to tanh to the default rectified linear unit (ReLU).
. The choice for ranges from the sigmoid to tanh to the default rectified linear unit (ReLU).
require "nn"model = nn.Sequential()model:add(nn.Linear(2,10))
model:add(nn.Tanh())
model:add(nn.Linear(10,1))
The result of this model is starting to look like the target function. So we’re on the right track.
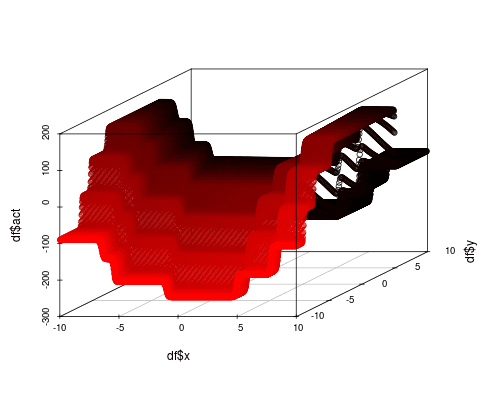
However, the result is rather blocky. This suggests that there are not enough parameters to properly capture the nonlinearity. By increasing the hidden layer to 40 nodes, we can smooth this out further.
Development Notes
I used Torch to generate the training set and the neural networks. To analyze the results I used standard R.
Training the network requires a test dataset. I generated one (called trainset below) using Lua that conformed to the Torch spec for row-major datasets. To train the model, I used the SmoothL1Criterion coupled with stochastic gradient descent. Good results require fiddling with the learningRate and the learningRateDecay on the trainer. (I don’t include these parameters as this is related to an exercise for my students.)
criterion = nn.SmoothL1Criterion()trainer = nn.StochasticGradient(model, criterion)trainer:train(trainset)
To render the plots, I evaluate the trained model against the complete training set and write out a CSV. Then I load into R and use the scatterplot3D package to render the surface.
Conclusion
Function approximation is a powerful capability of neural networks. In theory any function can be approximated, but constructing such a network is not so trivial. One of the key lessons with neural networks is that you cannot blindly create networks and expect them to yield something useful. Not only does it take patience, but it takes an understanding and appreciation of the theory to lead you down the correct path.
Brian Lee Yung Rowe is an Adjunct Professor at the CUNY MS Data Analytics program and also the founder of Pez.AI, a chat-based data analysis and computing platform with a conversational AI interface. This article is reformatted for this blog. View the original on Cartesian Faith.
){kind=link}