
My nephew’s a very impressive young man. Five years ago, he received a PhD in Biochemistry/Molecular Biology from a prestigious university, earning numerous teaching and research awards along the way. He then took a faculty position at a college where, several years later, he decided to become literate in analytic computation in addition to executing his teaching and research responsibilities.
He’s become proficient in R, completing the Coursera Data Science Specialization from Johns Hopkins, along with other courses/self-study endeavors including SQL, bioinformatics/Bioconductor, Statistics with R for the Life Sciences, and Advanced Statistics for the Life Sciences. At this point, he’s a true data scientist, leveraging his strong science background with newly-developed computation and analytic skills.
As he’s progressed, we’ve had occasional Skype video sessions to discuss aspects of R, RStudio, and SQL. Before one session a while back, he asked if we could focus on outer joins and correlated sub-queries, advanced topics from his then SQL course. Before the call, I decided to access some readily-accessible data in R and assemble a few R/SQL scripts that illustrate those advanced queries in action.
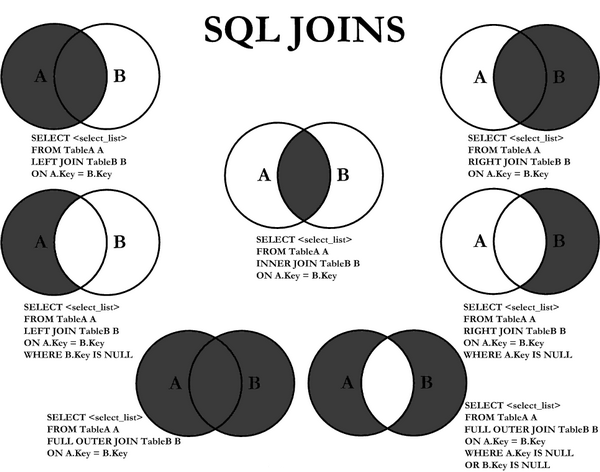
In SQL, an equi or inner join is one that links tables on exact matches of the join attribute(s). Rows from either table that are unmatched in the other are not returned. With outer joins, in contrast, unmatched rows in one or both tables can be returned. A left join, for example, returns matched rows plus unmatched rows from the left table only. I often use left joins in data wrangling.
A correlated sub-query is a query nested inside another query that uses values from the outer to probe the inner. Very powerful, the correlated sub-query operates like computationally expensive nested loops and must subsequently be used prudently.
The scripts to showcase the SQL queries for our call used R and it’s database interface, DBI, with the MonetDBLite SQL engine. The R package nycflights13, comprised of five data.frames, provided the data foundation.
I recently upgraded the code to a Jupyter Notebook with Microsoft Open R 3.4.4. In addition, I wrote several functions to ecapsulate the MonetDBLite SQL after pushing the data.frames into MonetDB tables. flightsdb, consisting of 336776 records, is the “fact” table, with dimensions airlinesdb, airportsdb, planesdb, and weatherdb. Conveniently, count queries with flightsdb as a left outer join illustrate well the concepts my nephew wanted to see. It’s also easy to probe the hits and misses counts of these joins with correlated sub-queries. The remainder of this notebook details the code and results of the inquiry.
BTW, my nephew got the gist of outer joins and correlated sub-queries immediately. And now, armed with computation and analytic skills, he’s looking to switch from academia to commercial data science. Some lucky company will reap the good fortune of hiring him.
Read the entire article here.
{kind=link}