
Length of Stay (LOS) is a critical factor in managing hospital quality & economic outcomes in Healthcare. The metric is calculated by summing the total number of days for all discharges & dividing it by the total number of discharges. Insurance programs such as Medicare are moving to a model where they are compensating Hospitals the same amount for a specific surgery (e.g. Joint replacement) regardless of the number of days spent in the hospital. Therefore, hospitals & the overall healthcare ecosystem are motivated to reduce LOS.
Dexur analyzed large scale medical claims data set to identify LOS by discharge code for all hospitals. We also aggregated & summarized raw data to enable easy machine learning modelling & predict LOS. If you are a healthcare researcher, who wants access to these data sets, please contact us & we can work on collaborating on a project. A simple of the illustration of the top Discharge Groups (DRGs) by Length of Stay at Mayo Clinic at Rochester is given below.
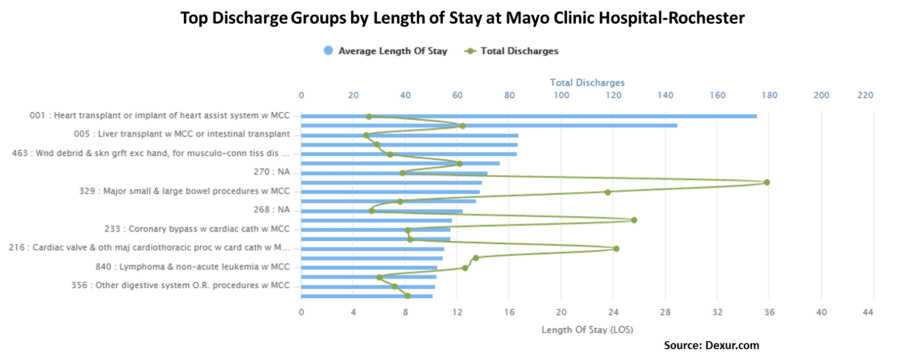
To get your creative juices going, here are five Machine learning research projects that you can read to better understand how to predict LOS in Hospitals.
1) Length of Stay Prediction and Analysis through a Growing Neural Gas…: Length of stay (LoS) prediction is considered an important research field in Healthcare Informatics as it can help to improve hospital bed and resource management. The health cost containment process carried out in Italian local healthcare systems makes this problem particularly challenging in healthcare services management. In this work a novel unsupervised LoS prediction model is presented which performs better than other ones commonly used in this kind of problem. The developed model detects autonomously the subset of non-class attributes to be considered in these classification tasks, and the structure of the trained self organizing network can be analysed in order to extract the main factors leading to the overcoming of regional LoS threshold.
2) IMPROVED PREDICTION OF HOSPITAL LENGTH OF STAY FOR SEVERE INJURY: There are limited beds in hospital trauma wards, and yet there is a constant demand for these beds by the inflow of severely injured patients. Many patients are initially allocated to these beds when they could be better treated in another specialised ward. If we could accurately classify patients with hospital length of stay (LOS) of 2 days or less versus those who require longer stays, we could make a more informed decision whether or not to place them in another ward when they are admitted, rather than wasting time and resources transferring them to another ward later. We systematically investigate feature transformation and selection techniques in the construction of a LOS prediction model for trauma patients. We also apply and evaluate a comprehensive range of classification algorithms on data from the trauma domain as well as from a general hospital setting. In addition, we propose a new nearestneighbour (NN) algorithm, ranked NN, which takes into account the predictive relevance of features when computing the distance to the nearest neighbors.
3) MACHINE LEARNING TECHNIQUES FOR PREDICTING HOSPITAL LENGTH OF STAY …: In this paper, we compare three different machine learning techniques for predicting length of stay (LOS) in Pennsylvania Federal and Specialty hospitals. Using the real-world data on 88 hospitals, we compare the performances of three different machine learning techniques—Classification and Regression Tree (CART), Chi-Square Automatic Interaction Detection (CHAID) and Support Vector Regression (SVR)—and find that there is no significant difference in performances of these three techniques. However, CART provides a decision tree that is easy to understand and interpret. The results from CART indicate that psychiatric care hospitals typically have higher LOS than nonpsychiatric care hospitals. For non-psychiatric care hospitals, the LOS depends on hospital capacity (beds staffed) with larger hospitals with beds staffed over 329 having average LOS of 13 weeks vs. smaller hospitals with average LOS of about 3 weeks.
4) A Comparison of Supervised Machine Learning Techniques for Predicti…: Diabetes is a life-altering medical condition that affects millions of people and results in many hospitalizations per year. Consequently, predicting the length of stay of inhospital diabetic patients has become increasingly important for staffing and resource planning. Although statistical methods have been used to predict length of stay in hospitalized patients, many powerful machine learning techniques have not yet been explored. In this paper, we compare and discuss the performance of various supervised machine learning algorithms (i.e., multiple linear regression, support vector machines, multi-task learning, and random forests) for predicting long versus short-term length of stay of hospitalized diabetic patients.
5) Real-time prediction of inpatient length of stay for discharge prio…: Hospitals are challenged to provide timely patient care while maintaining high resource utilization. This has prompted hospital initiatives to increase patient flow and minimize nonvalue added care time. Real-time demand capacity management (RTDC) is one such initiative whereby clinicians convene each morning to predict patients able to leave the same day and prioritize their remaining tasks for early discharge. Our objective is to automate and improve these discharge predictions by applying supervised machine learning methods to readily available health information. The authors use supervised machine learning methods to predict patients’ likelihood of discharge by 2 p.m. and by midnight each day for an inpatient medical unit. Using data collected over 8000 patient stays and 20 000 patient days, the predictive performance of the model is compared to clinicians using sensitivity, specificity, Youden’s Index (i.e., sensitivity þ specificity – 1), and aggregate accuracy measures.
{kind=link}