
Deep Learning is a new area of Machine Learning research that has been gaining significant media interest owing to the role it is playing in artificial intelligence applications like image recognition, self-driving cars and most recently the AlphaGo vs. Lee Sedol matches. Recently, Deep Learning techniques have become popular in solving traditional Natural Language Processing problems like Sentiment Analysis.
For those of you that are new to the topic of Deep Learning, we have put together a list of ten common terms and concepts explained in simple English, which will hopefully make them a bit easier to understand.
Perceptron
In the human brain, a neuron is a cell that processes and transmits information. A perceptron can be considered as a super-simplified version of a biological neuron.
A perceptron will take several inputs and weigh them up to produce a single output. Each input is weighted according to its importance in the output decision.
Artificial Neural Networks
Artificial Neural Networks (ANN) are models influenced by biological neural networks such as the central nervous systems of living creatures and most distinctly, the brain.
ANN’s are processing devices, such as algorithms or physical hardware, and are loosely modeled on the cerebral cortex of mammals, albeit on a considerably smaller scale.
Let’s call them a simplified computational model of the human brain.
Backpropagation
A neural network learns by training, using an algorithm called backpropagation. To train a neural network it is first given an input which produces an output. The first step is to teach the neural network what the correct, or ideal, output should have been for that input. The ANN can then take this ideal output and begin adapting the weights to yield an enhanced, more precise output (based on how much they contributed to the overall prediction) the next time it receives a similar input.
This process is repeated many many times until the margin of error between the input and the ideal output is considered acceptable.
Convolutional Neural Networks
A convolutional neural network (CNN) can be considered as a neural network that utilizes numerous identical replicas of the same neuron. The benefit of this is that it enables a network to learn a neuron once and use it in numerous places, simplifying the model learning process and thus reducing error. This has made CNNs particularly useful in the area of object recognition and image tagging.
CNNs learn more and more abstract representations of the input with each convolution. In the case of object recognition, a CNN might start with raw pixel data, then learn highly discriminative features such as edges, followed by basic shapes, complex shapes, patterns and textures.

source: http://stats.stackexchange.com/questions/146413
Recurrent Neural Network
Recurrent Neural Networks (RNN) make use of sequential information. Unlike traditional neural networks, where it is assumed that all inputs and outputs are independent of one another, RNNs are reliant on preceding computations and what has previously been calculated. RNNs can be conceptualized as a neural network unrolled over time. Where you would have different layers in a regular neural network, you apply the same layer to the input at each timestep in an RNN, using the output, i.e. the state of the previous timestep as input. Connections between entities in a RNN form a directed cycle, creating a sort of internal memory, that helps the model leverage long chains of dependencies.
Recursive Neural Network
A Recursive Neural Network is a generalization of a Recurrent Neural Network and is generated by applying a fixed and consistent set of weights repetitively, or recursively, over the structure. Recursive Neural Networks take the form of a tree, while Recurrent is a chain. Recursive Neural Nets have been utilized in Natural Language Processing for tasks such as Sentiment Analysis.
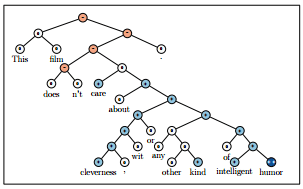
source: http://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf
Supervised Neural Network
For a supervised neural network to produce an ideal output, it must have been previously given this output. It is ‘trained’ on a pre-defined dataset and based on this dataset, can produce accurate outputs depending on the input it has received. You could therefore say that it has been supervised in its learning, having for example been given both the question and the ideal answer.
Unsupervised Neural Network
This involves providing a programme or machine with an unlabeled data set that it has not been previously trained for, with the goal of automatically discovering patterns and trends through clustering.
Gradient Descent
Gradient Descent is an algorithm used to find the local minimum of a function. By initially guessing the solution and using the function gradient at that point, we guide the solution in the negative direction of the gradient and repeat this technique until the algorithm eventually converges at the point where the gradient is zero – local minimum. We essentially descend the error surface until we arrive at a valley.
Word Embedding
Similar to the way a painting might be a representation of a person, a word embedding is a representation of a word, using real-valued numbers. Word embeddings can be trained and used to derive similarities between both other words, and other relations. They are an arrangement of numbers representing the semantic and syntactic information of words in a format that computers can understand.
Word vectors created through this process manifest interesting characteristics that almost look and sound like magic at first. For instance, if we subtract the vector of Man from the vector of King, the result will be almost equal to the vector resulting from subtracting Woman from Queen. Even more surprisingly, the result of subtracting Run from Running almost equates to that of Seeing minus See. These examples show that the model has not only learnt the meaning and the semantics of these words, but also the syntax and the grammar to some degree.
So there you have it – some pretty technical deep learning terms explained in simple english. We hope this helps you get your head around some of the tricky terms you might come across as you begin to explore deep learning.
This blog was originally published on the AYLIEN Text Analysis blog.
{kind=link}