

In this short article, I’ll try to capture the main differences between the MLops tools Ploomber and Kubeflow. We’ll cover some background on what is Ploomber, Kubeflow pipelines, and why we need those tools to make our lives easier.
We’ll see the differences in 3 main areas:
1. Ease of use
2. Collaboration and fast iterations
3. Debugging, Testing and reproducibility
So let’s dive in!
Background
Let’s start with a short explanation of what a common data/ML workflow looks like, why do we even need orchestration and how it will help you perform your job better and faster.
Usually, when an organization has data and is looking to produce insights or predictions out of it (to drive a business outcome), they bring in Data Scientists or MLEs to explore the data, prepare it for consumption and generate a model. These 3 assignments can be then unified into a data pipeline with correlating tasks, getting the data, cleaning it, and training a model. This architecture is pretty basic for a data pipeline, we’ll have an input and output for each of the tasks, and that’s what defines the dependencies within the pipeline.

Architecture of ML-Basic: A sample of all of the tasks we’re running (get data, engineer the features, join the data) to fit our model. (I found it way easier to explain on the plot instead of diving into the code, the whole “A picture is worth a thousand words”)
What is orchestration? Why do we need it?
The moment we add more tasks to the pipeline it suddenly becomes way more complex. In some cases, especially in production environments the pipeline has parallel tasks and those can have one-to-many inputs and outputs but it always starts in one place and ends in another. Often, this is referred to as a direct acyclic graph (DAG). A DAG is a representation of the ML workflow and in most common frameworks today like Ploomber, Kubeflow, Airflow, MLflow, and many more, it’s the way to control and display the data pipeline. Yes, this is the same DAG concept from your algorithms course! (those of you who took it). Once this representation of each task is defined, the orchestrator then will follow its order and execute each task, its dependencies, and outputs, and will retry if necessary (we can look at the DAG above for reference).
Kubeflow vs Ploomber
Now to the main course, we have some understanding of basic data pipelines, common structures, and concepts and why we need those. We’ll review these two tools from 4 different angles to understand the differences and when you will need to use each of the tools.
Ease of use
The value of a tool is derived in my opinion from the overall experience – setup, extra steps, maintenance, and the ease of use in each of those steps. When I had to deploy a Kubeflow cluster, the first roadblock I hit was the documentation, tons of pages and options to deploy, in addition to that I had later discovered that I couldn’t run locally on my laptop which is pretty basic if you want to test your work BEFORE even thinking of production. Most of the data science projects start as “research experiments” and it’s not certain they can make it into production. One of the first questions is if the data is right, and do we have enough of it? The best idea here is to quickly start iterating on these questions by spinning a local environment instead of a huge setup.
Now back to setting it up, I’ve also discovered there are two versions after installation so I kept using the old one (no way I was going through this long installation again). Once the cluster was configured on the cloud account I opened for it, I realized I had to use complex APIs for python and there were some limitations to run on top of docker (had to keep the tasks as free text). During this process, I’ve tried one of the frameworks that were supposed to ease all of it for me, especially with notebooks, Kale – but without success. Now on the other hand, with Ploomber it was straightforward to start locally, all I had to do is run pip install ploomber I could then start from a template pipeline and develop it on my laptop. The docs are structured in a way that every use case has a cookbook and the concepts are explained in one place. It allows deployment both locally and in the cloud so once the iterations were done I could just submit a job to my Kubeflow cluster. There are CLI APIs for basic actions and python API for more advanced users.
Collaboration and fast iterations
On Kubeflow when I needed to run through a container every time it pulled the image and took about 1 minute to start running the tasks. In addition, I couldn’t really log into the container and see what’s going on, basic stuff like which image is being used, what dependencies are currently used, etc. The outputs in containers were extremely hard, there was a specific location I could save them, without parameterizing at all. Eventually, I had to use cloud storage to allow faster iterations. In Ploomber, I could simply use a pip virtual env/conda and lock the versions the way I wanted it (this is highly relevant in production environments where Jupyter has limited access to new packages). In addition, since the code is running locally through python, I could iterate on each of the tasks and understand exactly what’s going on, without creating a whole new pipeline for it or changing the code. You can define exactly where the outputs are being saved, locally or to the cloud. In addition, since the notebook code is being translated to scripts, I could push my code into Git and collaborate with the rest of the data science team.
Debugging, Testing and reproducibility
Since Kubeflow (or at least the MiniKF I was running) runs on a cloud cluster, and the code runs inside a container, it’s pretty hard to debug and test the code. I could not find anywhere in their documentation how I can log into the container and start a debugging session. This made testing the code very difficult. In addition to that, since you can’t log into the running environment and see what’s the current data frames and the different artifacts it’s literally impossible to reproduce each run. On the other hand, in Ploomber not only it’s local so immediately you can start a debugging session, you can also log into your docker container and understand the dependencies. It’s way easier to test your code when it’s modular and you don’t need to wait for an entire pipeline to run.
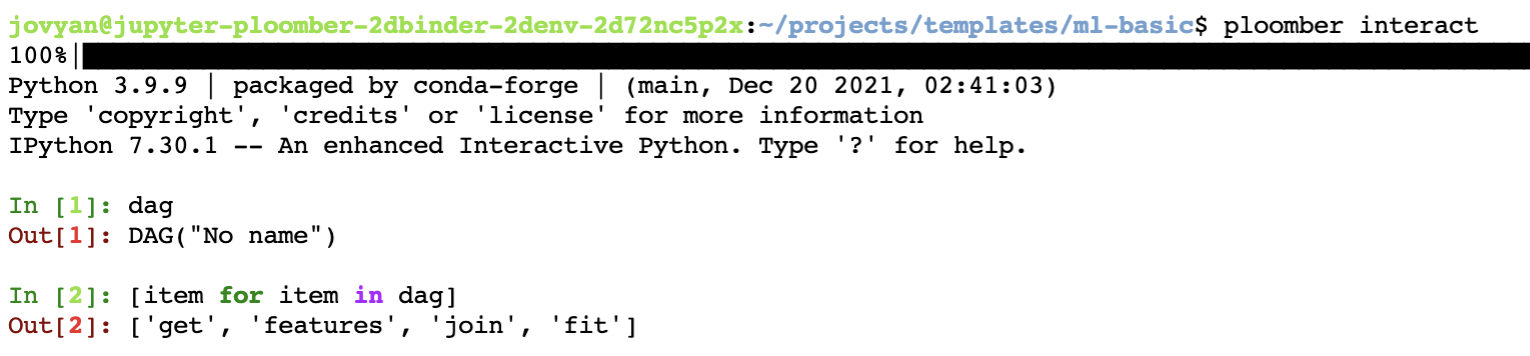
An example of an interactive session inside the Jupyter instance, viewing the DAG and its tasks compared to a black box running remotely.
When Kubeflow will make sense
In case you have a pipeline ready, and you’re looking for a high-performance cluster to deploy it on, meaning after all of the interactive data exploration, analysis and iterations then that’s a good use case for Kubeflow. When you’re early on the process, in need to iterate fast on the data and tweak the pipeline, Ploomber will be the better fit since it streamlines this process. You can quickly iterate on your workflows, move faster and when you’re ready, the Kubeflow connector will allow you to deploy the final data pipeline seamlessly.
Conclusion
Overall this was an enlightening experience for me, understanding all of the gaps in the existing Kubeflow architecture and bringing the solutions through Ploomber. I believe that data science and MLops work should be easy, maintainable, and reusable. I understand the niche that Kubeflow is going for, and I hope that V2 is producing a better smooth experience for their users. In dev-tools and infrastructure it’s highly important to go for tools that not only solve the problem but also are easy to onboard new people and that its maintenance is friendly (like Ploomber!), after all, the chances the tool will be replaced in a few months aren’t high.
You can also explore Ploomber in greater depth, including how to visualize with Ploomber.
{kind=link}