

NLQ or Natural Language Query or Text-to-SQL or NL2SQL is an arm of computational linguistics, that helps users to fetch required data, visualizations, and insights, from sentences written in human language. As a business user, knowing data schema, table and column names, knowing metadata, having technical know-how of a BI tool or data querying skills could be a daunting task. Though the skills of a data analyst are seeping into every job description, getting the required data could still be unnerving.
It is naive to assume that everyone in the organization knows the exact schema of each database, the role every entity plays in the query, and every join-paths that can be followed. Remember how confusing at times it might become to write an undemanding JIRA filter. Now replace it with the ease of just putting down your requirement in form of a sentence and voila, you have your data table in front of you, with a beautiful, contextual visualization – possibly a bar or pie chart, but not limited to these two only.
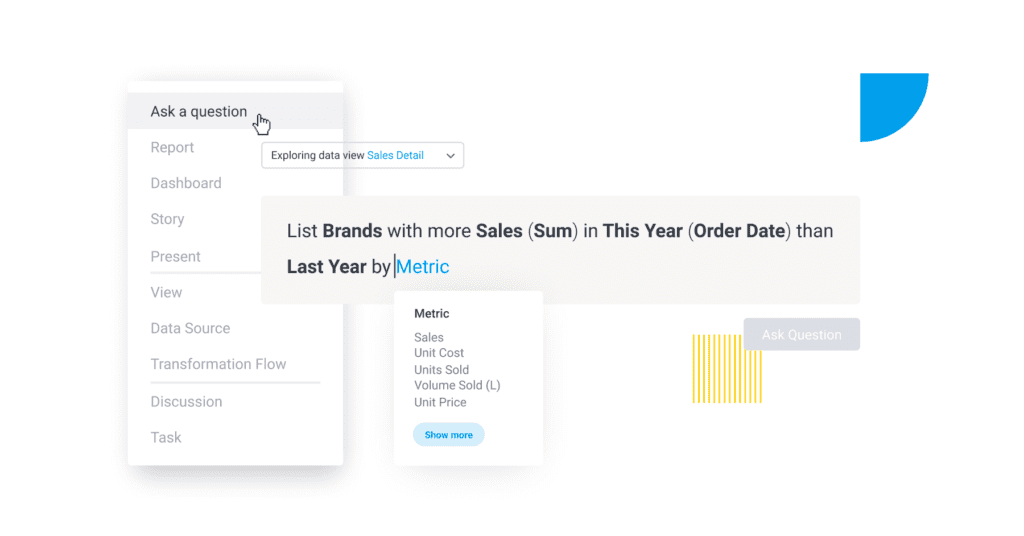
Lets see how complex a query can be, for a simple data point:
What is the last month sales of west region?
SELECT SUM(ps.sales) FROM Prod_Sale ps JOIN Region r ON ps.region_id = r.region_id WHERE r.region = “west” AND DATEPART(month, ps.sale_date) = (DATEPART(month, GETDATE()) - 1) AND DATEPART(year, ps.sale_date) = DATEPART(year, DATEADD(m, -1, GETDATE()))
Show me the YoY increase in per store monthly footfall in west region
let’s avoid the complications 🙂
The asked information or ‘utterance’ can be as simple as getting the total sales to as complex as getting the change in a calculated metric – per store footfall. Identifying the ‘intent’ & ‘entity’ is the prime challenge of NLQ, since this would be core to identify structural dependencies, database column mapping and backend query generation.
Intent = getting sales
Entity = [last month] [west region]
With several traditional and AI/ML based solutions available, to narrow down and implement could be baffling. Some of the available solutions are:
| Traditional | AI/ML | Libraries | ||
| ATHENA, NaLIR, SPARKLIS, NLQ/A, SODA, AskNow, USI Answers | EditSQL, SEQ2SQL, SQLova, X-SQL, HydraNet | Apache OpenNLP, AWS Comprehend, spaCy, Stanford CoreNLP |
It is essential to understand the requirement to be able to choose from multitude of such implementation approaches. One can pick up from the list mentioned below:
- Complexity of queries: What would be the query types, the system intended to support. Are they going to be simple keywords – ‘Electronics revenue’, or would support complex query structures like ‘Which product category has the highest sales this quarter’ or a near-SQL statement ‘find revenue, unit sold, product type, seller name where product category equals electronics’
- Computational performance: This is based on the different motivations and the algorithms these standard solutions are based on. Computational efficiency and speed are prime for scalability and user experience. Usage as part of a SaaS based solution can easily snowball.
- Languages supported: A multi-language (e.g. Spanish, Hindi and German with English) query support is made feasible by AI/ML based solutions but provisioning has to be made for similar training data.
- License cost: How much will piggy backing on a standard solution will cost and what appetite do we have as an implementer. Is it free or fixed charged or charged per usage.
- Training: The key advantage of AI/ML based solutions over traditional ones is they can support a wide range of linguistic variability giving more breadth to users to form queries. However this comes at a cost of having a huge training dataset. Traditional approaches have no such limitation of training dataset. While traditional parsing based solutions excel at identifying the sub-queries, the grammar based solutions guide users in typing right query.
- Coding language and support: Which programming languages are supported for APIs and if Dockerization would be possible. How large is the community and responsive the support team is, make a huge difference to ease of development and decreasing time to market.
- Semantics: How and up to what extent, the semantic difference between query and database will be handled. e.g., the query may look like ‘what was the revenue last week’ while in database last week would be represented by actual dates.
- Preprocessing: An approach many involve few or many of the NLP processes. What are the company’s appetite for complexity, skill set of the team and time limitations of delivery? These are some of the basic questions to answer before choosing a complex but high fidelity system. Some of the processing steps could involve:
- Named Entity Recognition
- Tokenization
- Stop word
- Parsing
- Stemming/lemmatization
- Parts of speech tagging
- Synonym
- Fuzzy logic spell check
- Training data generation
- Interpolation/Extrapolation of nearest neighbor word
- Back translation
- Character insertion, swap, deletion
- Slot filling for missing words
These were the primary analysis points we considered, while implementing a similar solution which we named, ‘Data-On-Demand’, for the Human Capital Management tool – Saba (a Cornerstone product). This was a major step towards commitment to democratization of data.
{kind=link}