

The same day OpenAI released Generative Pre-Trained Transformer 4 (GPT-4), online education tools nonprofit Khan Academy announced that GPT-4 had already been added to the organization’s interactive tutoring system.
Founder Sal Khan acknowledged the shortfalls of large language models (LLMs) that Data Science Central readers are well familiar with. But he confirmed the nonprofit’s commitment to adopting leading-edge technology regardless, saying “We view it as our responsibility to start deeply working with artificial intelligence, but threading the needle so that we can maximize the benefits, while minimizing the risks.”
In a demo, Khan highlighted the measures Khan Academy is taking to try to ensure the experience for students, parents and teachers is a safe one :
- Parents and teachers can check on students as they interact with the tutor and engage in learning activities. “Parents and teachers can see everything students are up to,” he noted.
- “We’re also being careful to make sure we’re not passing personally identifiable information to the actual artificial intelligence.”
- “We’re also not using student data to train (the AI).”
- Besides guardrails around the tool, “We’re also putting guardrails around the activities, so that students can only use it to learn, and not use it to cheat.”
- If the students “do something a little bit off that might be harmful to themselves or others, parents and teachers will be notified.”
- Students can “craft a story,” with the tutor writing a paragraph, then the student writing one, the tutor another one, the student another, etc. In other words, the story crafting dialogue is structured so that the student has to contribute.
The GPT-4 enabled tutor can field questions or provide hints at any point in the session while generating practice exercises or engaging in debate, for example.
All of this interaction takes place within the prompt-oriented/Q&A conversational thread. Here’s an example of a vocabulary learning exercise customized to a sixth grader:
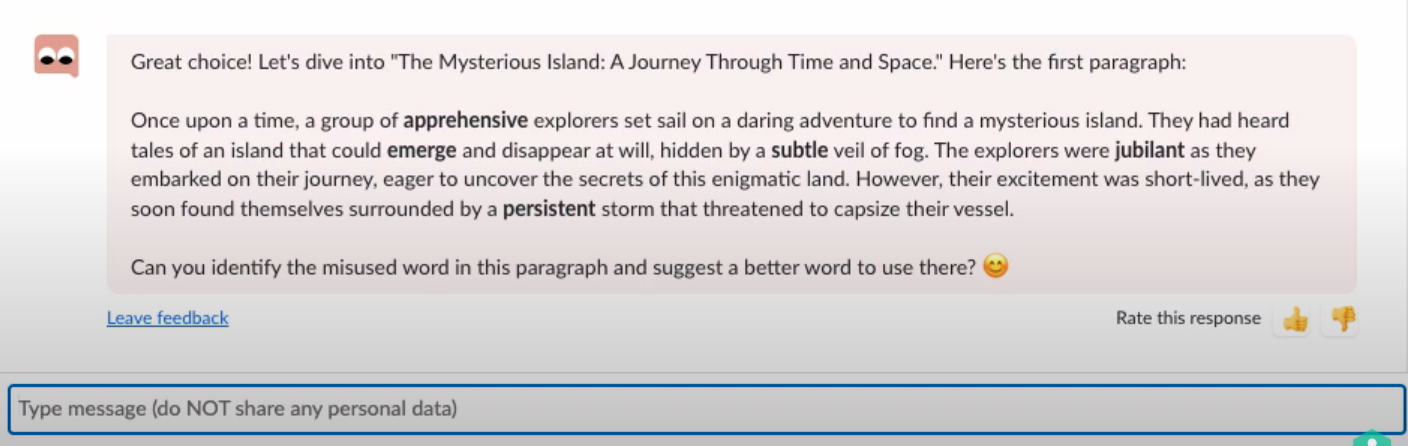
GPT-4 Khan Academy In Depth Demo, YouTube, March 2023
On the face of it, the Khan Academy approach seems well thought out and informed by its years of work web-scale online education. But what about external factors beyond the control of designers?
Although GPTx systems do not learn from user input, prompts from a user can influence how ChatGPT, for example, responds during a particular series of prompts.
NewsGuard reported in its February 2023 Misinformation Monitor that ChatGPT can be misled via a sequence of prompts to deliver narratives that contain falsehoods. 80 percent of the prompts a NewsGuard analyst provided triggered “answers that could have appeared on the worst fringe conspiracy websites or been advanced on social media by Russian or Chinese government bots.”
What’s worrisome to me is that OpenAI is painting a target on its own back by centralizing where its black box data quality effort happens. The more dependent users become on OpenAI’s offerings alone, the higher the risk of a single point of failure. Things don’t have to be this way.
Will bad actors and their followers poison the well for large language models?
OpenAI (Microsoft) and Khan Academy are both being diligent about identifying the threats posed to the LLMs they are using, as well as considering how to mitigate those threats. OpenAI, The Georgetown Center for Security and Emerging Technology, and Stanford’s Internet Observatory collaborated beginning in 2021 on disinformation threats and threat mitigation. A table from a paper summarizing the nature of the threats outlines five different classes of disinformation threats:
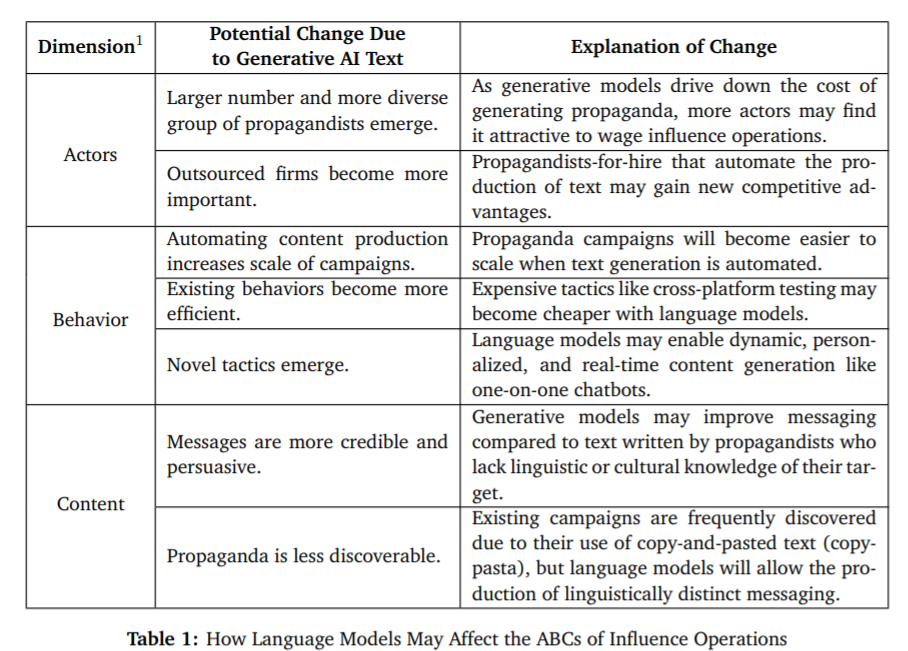
From “Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations,” Josh A. Goldstein, et al., arxiv.org, January 2023.
Additionally, although GPTx systems do not learn from user input, prompts from a user can influence how ChatGPT, for example, responds during a particular series of prompts.
NewsGuard reported in its February 2023 Misinformation Monitor that ChatGPT can be misled via a sequence of prompts to deliver narratives that contain falsehoods. 80 percent of the prompts a NewsGuard analyst provided triggered “answers that could have appeared on the worst fringe conspiracy websites or been advanced on social media by Russian or Chinese government bots.”
What’s worrisome to me is that OpenAI is painting a target on its own back by centralizing where its data quality effort happens. The more dependent users become on OpenAI’s offerings alone, the higher the risk of a single point of failure. Things don’t have to be this way.
Less GPTx navel gazing, more open collaboration
Better models will of course improve an LLM’s ability to separate fact from fiction, but GPTx algorithms are not the only way to deliver quality results.
Google has long worked on sifting the grain from the chaff on the open web when it comes to fact vs. fiction. In 2015, a Google paper on knowledge-based trust (KBT) described a statistical fact verification process, to reduce the amount of guesswork required in the data quality hunt.
In 2022, Olaf Kopp in SearchEngineLand pondered Google’s more evolved concept of expertise, authoritativeness and trust (E-A-T): “I can imagine that Google gets an overall impression of E-A-T of an author, publisher or website through many different algorithms (a.k.a, “baby” or ‘tiny’ algorithms).”
In other words, Google uses a variety of algorithms to analyze a variety of signals from a given website, painting a picture of the data/content quality of that site in a manner complementary to its core algorithms such as PageRank. Its algorithms take advantage of website owners’ own efforts to improve quality.
Of course, Google has encouraged and assisted website owners to use and refine existing schema.org content structuring for over a decade now. Rather than just focus on the content it’s downloaded and indexed from sites, Google’s been in the habit of providing feedback and help to users to improve the quality of the source content out on the web.
Another way to think about how to improve source data quality (and therefore trustworthiness) is to blend the statistical neural net approach of OpenAI with symbolic AI or knowledge representation methods–an approach called neurosymbolic or hybrid AI. Schema.org falls under the KR umbrella, and there are also partially or fully automated knowledge graph techniques that could also decentralize data quality efforts.
Let’s engage the content producers at the source to help with next steps in data quality that LLMs need to deliver. Neurosymbolic AI makes context, connections, and essential description logic explicit. By doing so, we can reduce the energy waste associated with bloated LLMs by making it possible to use less data to achieve comparable results.
Brian Bailey in Semiconductor Engineering noted in 2022 that “Machine learning is on track to consume all the energy being supplied, a model that is costly, inefficient, and unsustainable.” Of course we all want machine learning to be sustainable.
{kind=link}