

Robotic process automation (RPA) when it first gained attention five or so years ago disappointed me. Here was yet another stopgap measure, a digital form of tape and baling wire to temporarily join scripts of oft-repeated tasks in a specified workflow sequence across commonly used applications. RPA seemed quite brittle–wouldn’t you have to regenerate the tape-and-wire scripts if one of the UIs changed?
Despite these issues, banks seemed to be flocking to RPA as a means of reducing headcount. And Business Process Management (BPM), which was more generalizable than RPA, if less user-friendly, seemed to be fading into the sunset. Of course, it’s hard to tell how much RPA adoption has enabled more efficiency.
Many integration and automation methods that major software/SaaS/public cloud vendors have come up with have a primary objective: maintain or grow the revenue stream for the incumbent provider in question. The integration assumes certain investments in what’s most popular, particularly if it’s the provider’s offering that’s being used (or more likely, underused). Enterprise Resource Planning (ERP), for example, was followed by Customer Relationship Management (CRM), Supply Chain Management (SCM), etc.
25 years ago, ERP imposed a general, but rigid data model on users–the provider’s concepts in the provider’s language, from the provider’s viewpoint. The knowledge graph approach, by contrast, allows much more user flexibility–the ability to create and evolve a general model of the business, as well as specific contexts, or domains, within that business. Disambiguated entities and rich relationships are key to that modeling effort.
Standards-based knowledge graphs offer a path to integration scalability without having to commit to a particular provider’s requirements. Rather than handing your business model intellectual property (IP) off to a provider, your company can keep and refine it. And as the technology evolves, entity-event and other kinds of business process-oriented modeling are ending up in graphs to function alongside and in conjunction with KG knowledge bases. These standard graphs are designed to grow and evolve organically.
Knowledge Base + Entity-Event Graphs
Knowledge bases are chock full of definitions and comparisons, such as how to precisely define X and distinguish it from Y and Z, while at the same time grouping X, Y and Z in a class they all belong to. From a machine’s point of view, these KBs are compendia of concept disambiguations and logical analysis as well as a logical synthesis of similar items in tiers of categories, or layers of abstraction.
But beyond such trees/hierarchies/taxonomies, an ontology can articulate a model with more than two dimensions, a fundamental way large-scale data integration can harness the power and scalability of more highly articulated graphs.
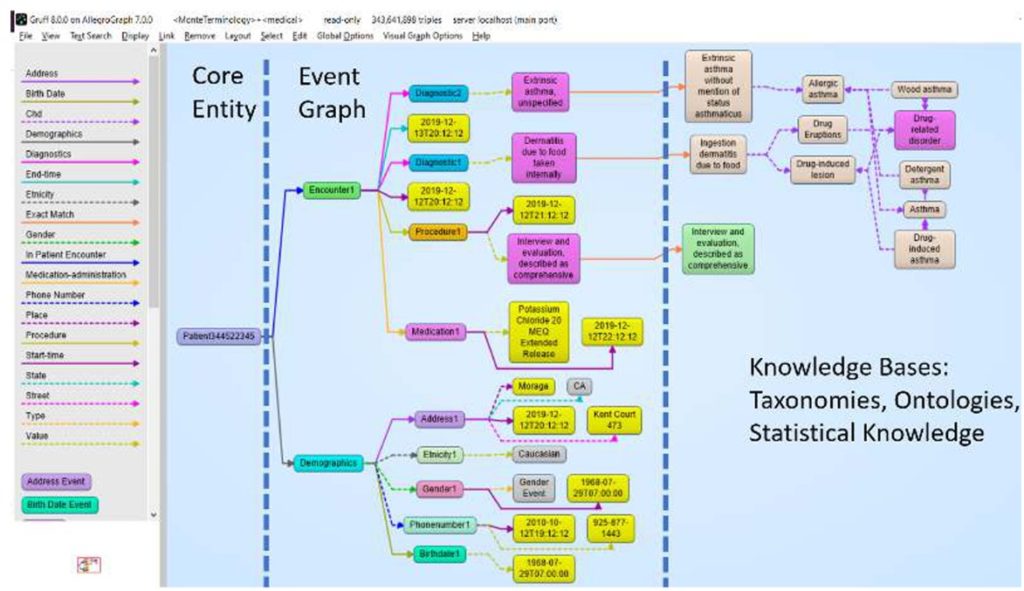
Different types of models can exist side by side and complement each other in the same large graph. Jans Aasman of Franz, the maker of Lisp tools and the Allegrograph RDF graph DBMS, has spoken and written on how Franz helped the Montefiore hospital chain in New York to model entity-event data and complement their knowledge base with event histories in the form of core entities and trees.
On the left side of the diagram below is a patient (the core entity), in the middle are the events, and on the right is the knowledge or fact base (e.g., SNOWMED medical terminology, Geonames geographical locations, etc.).
The left or entity-event side depicts a peanut allergy scenario and different phases of reaction and treatment. Sequencing and a degree of human readability of the unfolding ‘story’ have to be maintained, with trees of different types of events growing from the core entity.
Event-Centric Graphs and the use of Natural Language Processing
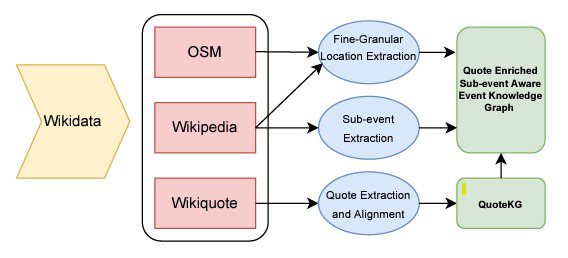
Research on event-centric knowledge graphs from academics such as Tin Kuculo of the L3S Lab at Leibniz University Hannover points out that the fact base/semantic web (right side, below) of the graph is more or less permanent or slow-moving, and abstracted at a higher level. It’s best to extract events and subevents from that side so that the left and right parts are directly related. Then NLP can be used to cluster similar quotes associated with the events and core entities (people) across different languages, for example. Those sets of quotes are collected in a subgraph which is then linked to the main graph.
Articulating processes within knowledge graphs to fill machine learning data gaps
Other use cases also benefit from semantic, entity-event style modeling. In a recent LinkedIn post, Thomas Kamps of ConWeaver points out that anti-money laundering efforts need to gain access to and collect data about entities that are spread across a plethora of online repositories. What that challenge implies is the need to map both context and causal relationships across systems boundaries, not to mention busted-up data cartels that prevent mere access to data.
The blending of entity-event trees (sequences of events) and knowledge bases that offer general, less frequently changing context about those same entities or classes of entities would seem essential. And the organic, evolving knowledge graph culture makes it much more possible to reduce observation bias–by emphasizing reuse and other lifecycle-oriented data management.
Kamps underscores the how this articulated knowledge graph data supplies machine learning demand for networked entity data:
“Business context is about data and the semantic interpretation of the data within the context of a business process. We must distinguish the reasoning about the data from the data themselves. AI and Machine Learning algorithms can only be as good as the training data they are fed with. Thus, if transactions are subject to investigation, e.g., w.r.t. to fraud detection or money laundering, it makes sense to feed ML technology with the network of entities that establishes the semantic context of the anticipated crime scenario.”
Judging by his most recent LinkedIn posts, Kamps has been evolving a KG-based automation approach to vehicle product development and management, which, unlike RPA, makes total sense to me.
As KGs become richer, business, process, and data management all become intertwined. A more holistic model of the business can emerge, and with it, much more utility.
{kind=link}