
“If you start by creating your data, then it’s like you are piling up some value or you’re creating some assets,” WordLift CEO Andrea Volpini told me in our recent FAIR Data Forecast interview. Volpini’s an advocate for adding structured data such as Schema.org to your content. That way, the content becomes logically connected and search engine optimized.
But even adding just simple associations to your data network enriches the content assets you’re creating. If you’re sharing associations through simple web annotations, you’re giving both machines and humans an outline of what you’re working on, the puzzle pieces you’re putting together, and a sense of the human-centered network you’re building.
A colleague in our personal knowledge graph working group, Gyuri Lagos, has been working on an interpersonal knowledge graph (KG). His projects in development that we’ve seen include Indyweb and Indyhub.
His vision of interpersonal KGs is twofold: 1) Collaboration and better data networking across and beyond web silos, and 2) an open source orientation unhindered by commercial concerns. The term Gyuri and I use to describe this kind of collaboration is “human centered”.
As people collaborate, they can nurture the online environment around them to echo, record, persist and interact with what’s around them. It’s a form of human-in-the-loop computing that evolves as collaboration takes place online.
“Web3” is a term the crypto community has co opted, but our working group is focused on the more webby aspects of decentralized, peer-to-peer data networking environments. Web and crypto are symbiotic, given that they’re both powered by digital hash tables (DHTs) and related content addressing.
The peer-to-peer named data network or web3 orientation Gyuri’s harnessing is based on the Interplanetary File System (IPFS), a means of storing, sharing and collaborating publicly that promises more scalability, data sovereignty, and human-centered automation than via the conventional web. In other words, IPFS is a named data network, one that could deliver more network effects than either web 1 or web 2.
You may not have heard about IPFS, but Lockheed and Filecoin have been partnered since 2022 on an IPFS-based open source space communications/collaboration environment. IPFS is just as useful for other purposes here on earth. It’s foundational networked collaboration.
Gyuri does a lot of research on computer science, open web and knowledge graph-related topics, and the annotations he makes are broadly shareable. Gyuri’s web3 tools are inspired in part by Hypothes.is and Cryptpad.fr, which are both conventional web.
I’ve started to use IPFS for storage of meeting recordings, as well as Hypothes.is (for now) for my genealogy research and the sharing of that research.
Hypothes.is has become popular in academic circles. Colgate University, for example, is hosting an internal workshop in August 2023 on “Collaborative Reading and Social Annotation” within the context of Moodle, an open source learning platform. According to the workshop announcement,
Hypothes.is is a digital tool that enables students and instructors to collaboratively read and annotate PDFs and web pages. When used inside of Moodle, Hypothes.is makes this marginalia open to all users in a course, thereby transforming reading and meaning-making into a collaborative, shared experience.
Initial impressions of Hypothes.is– A genealogy research example
Collaborative annotation using a tool like Hypothes.is starts with the use of a Chromium browser such as Brave, Chrome, Edge or Opera. When using Chrome, the ‘h.’ extension icon appears in the upper right corner of the browser tab you’re in. By default, it’s grayed out and inactive to begin with. Click on it at a public page you’ve landed on, and it turns black. Then you can annotate or highlight.
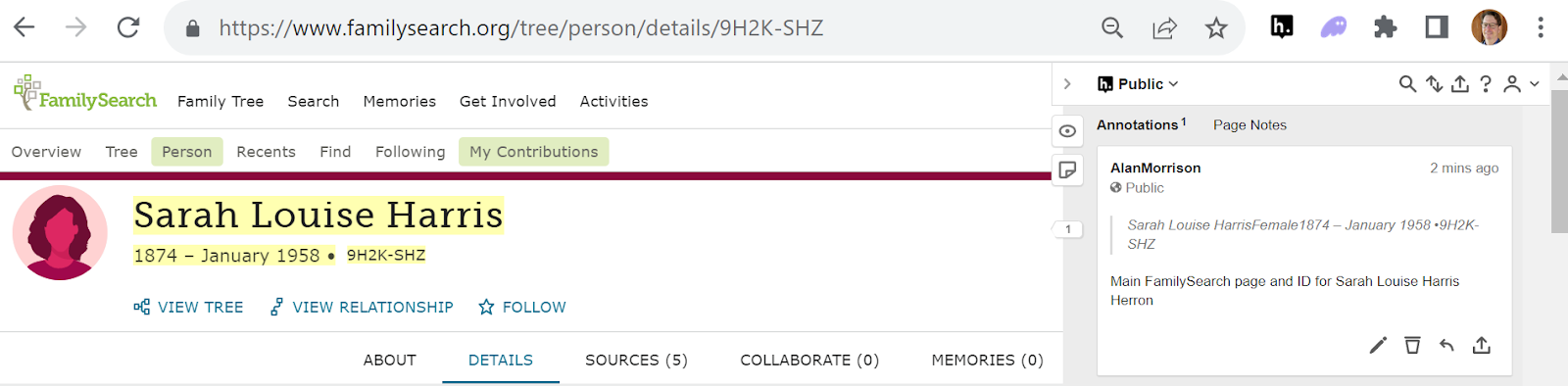
Yesterday, I was researching a relative who passed away the year I was born. Before Hypothes.is. I was frustrated by all the content artifacts I was leaving scattered across the web. I input my main family tree research findings on FamilySearch.org, the massive online genealogy collaboration and documentation site the Church of Latter Day Saints (LDS) runs. FamilySearch is set up to support your family tree assertions with links to documentation. But I also do some data entry on FindAGrave.com, Wikitree and some other non-commercial sites.
On FamilySearch, there’s a way to add the FindAGrave link and summary info of the deceased that’s buried to the deceased’s record. I added that source to my relative’s FamilySearch page and tree yesterday.
I’m browsing constantly to find facts that might shed more light on a given relative’s life, as well as help document that life online.
While the individual sites demand user input using web forms for entry field by field into a shared database, Hypothes.is allows free-form annotation at the web pages you visit. You click on the ‘h.’, and it turns black, indicating Hypothes.is is active on that page. Then you select text and/or image(s) on the web page and then highlight or annotate. Here’s another view of the annotation I just did for my maternal great grandmother.
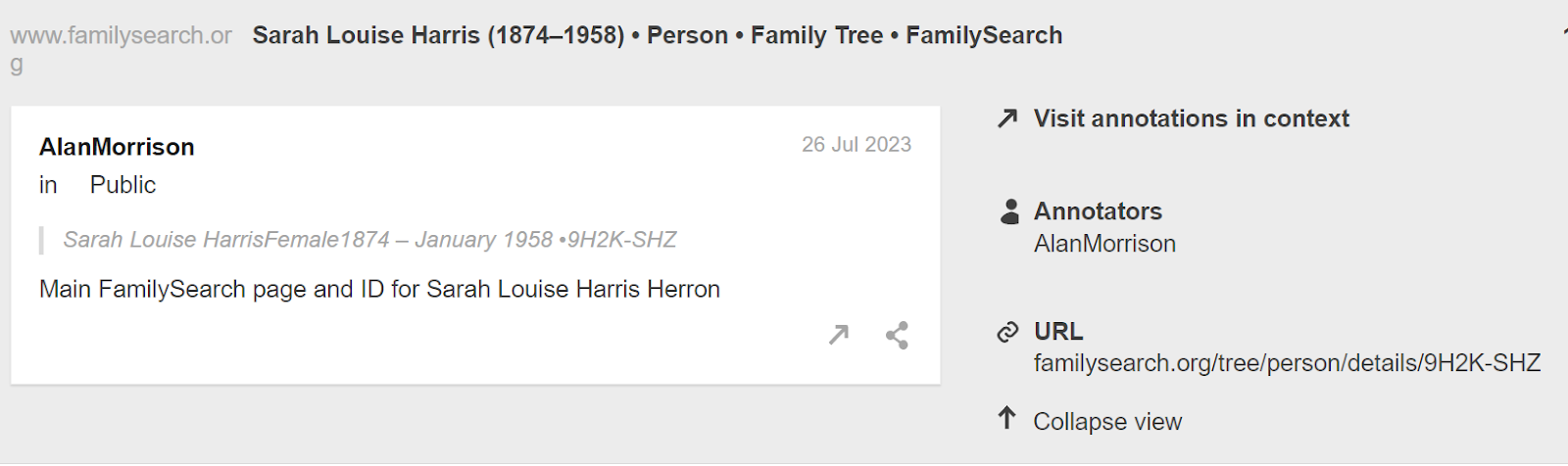
Another annotation I created was at the FindAGrave site:

The illustration below describes the browser extension interface for annotating web pages. I know there’s a lot more I could do with these annotations than I’ve just done. Creating useful annotations takes time and practice.
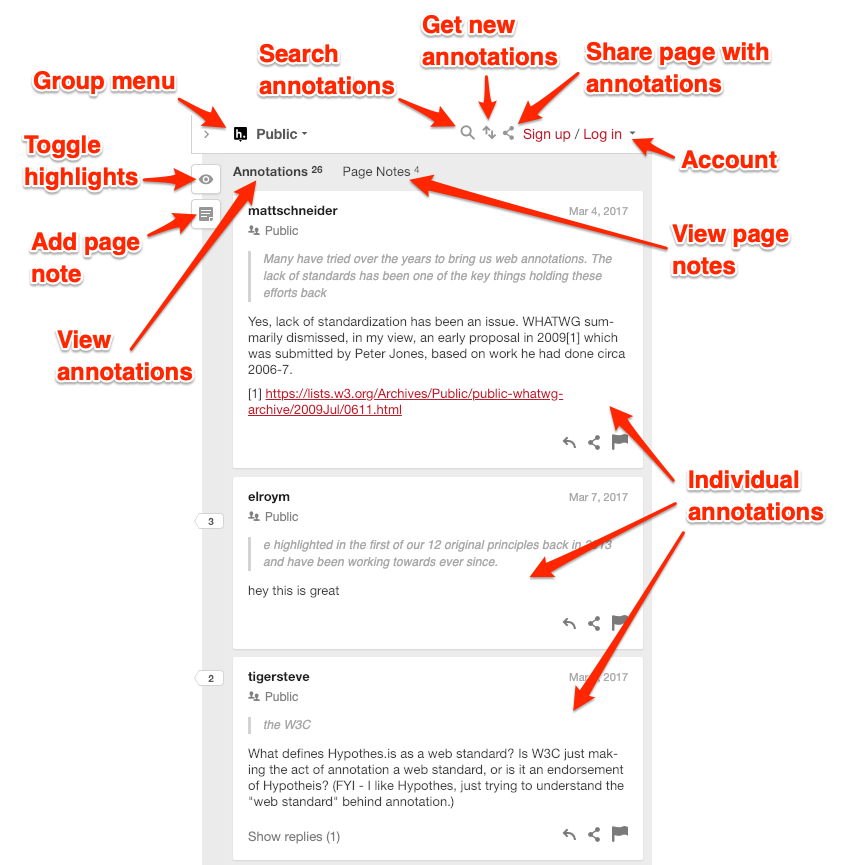
Source: Hypothes.is, 2023
Using annotation breadcrumb trails for research and community building
Volpini pointed out in my interview with him that adding logically connected associations to your own content helps to disambiguate and enrich your own online persona and personal brand.
In the case of interpersonal knowledge graphs, everyone in the community can contribute to the disambiguation and enrichment of the community’s online presence, and at the same time help with findability, accessibility, interoperability and reuse (the FAIR principles). And that applies not only to someone else finding your path to research discovery, but you being able to retrace your own steps whenever you need to.
{kind=link}