

In many cases, for an enterprise to build its digital business technology platform, it must modernize its traditional data and analytics architecture. A modern data and analytics platform should be built on services-based principles and architecture.
Introduction
part 1, provided a conceptual-level reference architecture of a traditional Data and Analytics (D&A) platform.
This part, provides a conceptual-level reference architecture of a modern D&A platform.
Parts 3 and 4, will explain how these two reference architectures can be used to modernize an existing traditional D&A platform. This will be illustrated by providing an example of a Transmission System Operator (TSO) that modernizes its existing traditional D&A platform in order to build a cyber-physical grid for Energy Transition. However, the approaches used in this example can be leveraged as a toolkit to implement similar work in other vertical industries such as transportation, defense, petroleum, water utilities, and so forth.
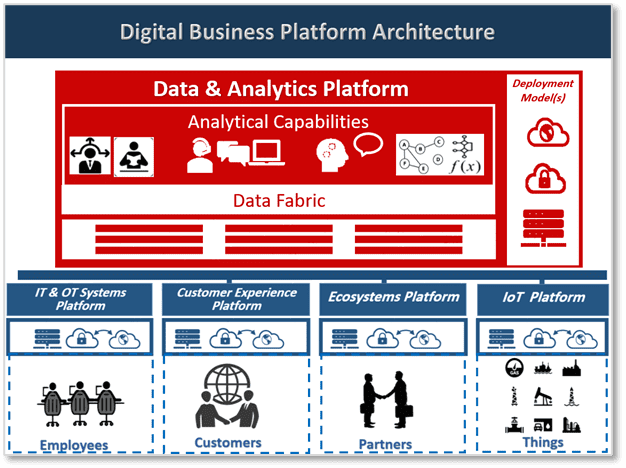
Reference Architecture of Modern Data and Analytics Platform
The proposed reference architecture of a modern D&A platform environment is shown in Figure 1. This environment consists of the modern D&A platform itself (which is denoted by the red rectangle at the left side of the figure), the data sources (at the bottom part of the figure), and the other four technology platforms that integrate with the D&A platform to make up the entire digital business technology platform (these platforms are shown in blue).
The reference architecture depicted in Figure 1 comprises several functional capabilities. From an enterprise architecture perspective, each of these functional capabilities includes a grouping of functionality and can be considered as an Architecture Building Block (ABB). These ABBs should be mapped (in a later stage of the design) into real products or specific custom developments (i.e. Solution Building Blocks).

Following is the description of the ABBs of the modern D&A platform reference architecture environment, classified by functionality:
- Audio: Data at rest audio files or data in motion audio streams
- BC Ledger: Data at rest blockchain ledger repositories or data in motion blockchain ledger streaming data
- Data at Rest Data Sources: Data sources of inactive data that is stored physically in any digital form (e.g. databases, data warehouses, data marts, spreadsheets, archives, tapes, off-site backups, mobile devices, etc.)
- Data in Motion Data Sources (Streaming): Data sources that generate sequences of data elements made available over time. Streaming data may be traversing a network or temporary residing in computer memory to be read or updated.
- Docs: Documents such as PDF or MS Office files
- ECM: Enterprise Content Management Systems
- ERP: Enterprise Resource Planning Systems
- Image: Data at rest imaging files or data in motion imaging streams
- IoT/OT Feeds: Data in motion streams fed from Internet of Things or operational technology real-time monitoring and control devices. The Internet of Things is the network of physical objects that contain embedded technology to communicate and sense or interact with their internal states or the external environment. Examples of operational technology real-time monitoring and control devices are the remote terminal units and programmable logic controllers.
- IT Logs: Data at rest logging files or data in motion logging streams. Logs are used to records either events that occur in an operating system or other software runs, or messages between different users of a communication software.
- Mobile: Mobile devices such as smart phones, tablets and laptop computers.
- Public Data Marketplace: An online store where people or other organizations can buy / sell data. In general, the data in this marketplace may belong to the enterprise or to third parties.
- RDBMS: Relational Database Management Systems
- Social/Web: Social media platforms such as Facebook and Twitter or web sites that host data or contents
- SQL/NoSQL: SQL or NoSQL Databases.
- Text: Text data sources such as emails or CSV files.
- Video: Data at rest video files or data in motion video streams.
The Digital Business Platform Architectural Building Blocks
- The IT & OT Systems Platform: This platform runs the core business applications, back office applications, infrastructure applications, endpoint device applications and operational technology applications
- The Customer Experience Platform: This platform run the customers and citizens facing applications such as customer portals, B2C and B2B
- The IoT Platform: This platform connects physical assets (Things) such as buses, taxis and traffic signals (for transportation domain), or power transformers and generator (for electrical power / utility domain) or oil wellheads (for Oil and Gas domain); for monitoring, optimization, control and monetization.
- The Ecosystems Platform: This platform supports the creation of, and connection to, external ecosystems, marketplaces and communities relevant to the enterprise business such as government agencies, smart cities, credit card networks, police, ambulance, etc.
- The D&A Platform: This platform contains the data management and analytics tools and applications
The Modern D&A Platform Architectural Building Blocks
The Data Fabric Layer
A data fabric is generally a custom-made design that provides reusable data services, pipelines, semantic tiers or APIs via a combination of data integration approaches (bulk/batch, message queue, virtualized, streams, events, replication or synchronization), in an orchestrated fashion. Data fabrics can be improved by adding dynamic schema recognition or even cost-based optimization approaches (and other augmented data management capabilities). As a data fabric becomes increasingly dynamic or even introduces ML capabilities, it evolves from a data fabric into a data mesh network. Data fabric informs and automates the design, integration, and deployment of data objects regardless of deployment platforms or architectural approaches. Data fabric utilizes continuous analytics and AI/ML overall metadata assets (such as location metadata, data quality, frequency of access, and lineage metadata, not just technical metadata) to provide actionable insights and recommendations on data management and integration design and deployment patterns. This approach results in faster, more informed, and, in some cases, completely automated data access and sharing. The data fabric requires various data management capabilities to be combined and used together. These include augmented data catalogs, semantic data enrichment, utilization of graphs for modeling and integration, and finally an insights layer that uses AI/ML toolkits over metadata graphs to provide actionable recommendations and automated data delivery. Following are the architectural building blocks of the data fabric:
The Data Hubs: A data hub is a logical architecture that enables data sharing by connecting producers of data (applications, processes, and teams) with consumers of data (other applications, processes, and teams). Endpoints interact with the data hub, provisioning data into it or receiving data from it, and the hub provides a point of mediation and governance, and visibility to how data is flowing across the enterprise. Each of the five platforms that make up the entire digital business platform may have one or more data hubs. In general, each of these platforms can exchange data with the other four platforms through their appropriate data hub(s).
The Data Connectivity: Provides the ability to interact with data sources and targets of different types of data structure, whether they are hosted on-premises, on public cloud, intercloud, hybrid cloud, edge, or embedded systems
Active & Passive Metadata Management: Provides the ability to manage metadata through a set of technical capabilities such as business glossary & semantic graph, data lineage & impact analysis, data cataloging & search, metadata ingestion, and translation, modeling, taxonomies & ontology, and semantic frameworks. A data catalog creates and maintains an inventory of data assets through the discovery, description, and organization of distributed datasets. Data cataloging provides context to enable data stewards, data/business analysts, data engineers, data scientists, and other lines of business data consumers to find and understand relevant datasets for the purpose of extracting business value. Modern machine-learning-augmented data catalogs automate various tedious tasks involved in data cataloging, including metadata discovery, ingestion, translation, enrichment and the creation of semantic relationships between metadata.
Data Integration: Provides the ability to integrate the different types of data assets through a set of technical capabilities such as ETL & Textual ETL, bulk ingestion, APIs, data virtualization, data replication, concurrency control, message-oriented data movement, streaming (CEP & ESP), blockchain ledger pooling service, data transformation and master data management. Textual ETL is the technology that allows an organization to read unstructured data and text in any format and in any language and to convert the text to a standard relational database (DB2, Oracle, Teradata, SQL Server, et al) where the text is in a useful meaningful format. Textual ETL reads, integrates, and prepares unstructured data that is ready to go into standard technologies such as Oracle, DB2, Teradata, and SQL Server. Once the unstructured data resides in any of those technologies, standard analytical tools such as Business Objects, Cognos, MicroStrategy, SAS, Tableau and other analytical and BI visualization technologies can be used to access, analyze, and present the unstructured data. These new applications can look at and retrieve textual data and can address and highlight fundamental challenges of the corporation that have previously been unrealized.
Data Governance: Provides the ability to support the governance processes of the different types of data assets through a set of technical capabilities such as policy management, rules management, security, privacy, encryption, bring your own key (BYOK), information lifecycle management, discovery and documenting data sources, regulatory and compliance management
Data Quality: Provides the ability to support the data quality processes of the different types of data assets through a set of technical capabilities such as data profiling, data monitoring, data standardization, data cleansing, data matching, data linking and merging, data enrichment, and data parsing and issue resolution
Augmented Data Management: Provides the ability to support and augment the data management processes of the different types of data assets through a set of technical capabilities such as ML & AI augmentation of main data management functions (e.g. data quality management, master data management, data integration, database management systems, and metadata management), automated/ augmented dataset feature generation, automated/ augmented DataOps and data engineering (e.g. data preparation, code and configuration management, agile project management, continuous delivery, automated testing, and orchestration), augmented data management performance tuning, data management workflow & collaboration as well as data administration & authorization intelligence
Data Lake: A data lake is a concept consisting of a collection of storage instances of various data assets. These assets are stored in a near-exact, or even exact, copy of the source format and are in addition to the originating data stores.
Logical DW/DV: Logical Data Warehouse /Data Vault: The logical data warehouse is conceptual data management architecture for analytics combining the strengths of traditional repository warehouses with alternative data management and access strategies (specifically, federation and distributed processing). It also includes dynamic optimization approaches and multiple use-case support. However, the architecture of the traditional repository part of the Logical DW can include architectural styles such as normalized schema, data marts (DM), data vault (DV), operational data stores (ODS), and OLAP cubes. The DV is a data integration architecture that contains a detail-oriented database containing a uniquely linked set of normalized tables that support one or more functional areas of business tables with satellite tables to track historical changes.
Private Data Marketplace: The private data marketplace (or enterprise data marketplace) is a company store for data, one that is accessible only to employees and invited guests. The enterprise data marketplace is distinctly different from commercial and open markets specifically because it is a marketplace for enterprise data. Think of it as the company store for data—a store that is accessible only to employees and invited guests. Enterprise data marketplace is to data markets what a corporate intranet is to the broader Internet.
ML Models & Analytics Artefacts Repository: Repository for storing the machine learning different models and data versions.
Metadata Repository (Relational/Graph): Repository for storing active and passive metadata of the different data assets. A RDBMS or Graph database may be used to store this metadata.
Master Data Repository: A Repository for storing the master data assets.
Data Persistence Performance Engine (Disk, SSD, RAM, Persistence RAM, …): Used for data caching to speed up the data analysis. It augments the capabilities of accessing, integrating, transforming, and loading data into a self-contained performance engine, with the ability to index data, manage data loads, and refresh scheduling.
The Analytic Capabilities Layer
Include the following analytical capabilities that support building and running business intelligence, data science, machine learning and artificial intelligence applications:
AutoML and Conversational UI: Automated Machine Learning provides methods and processes to make Machine Learning available for non-Machine Learning experts, to improve the efficiency of Machine Learning, and to accelerate research on Machine Learning. Machine learning (ML) has achieved considerable successes in recent years and an ever-growing number of disciplines rely on it. However, this success crucially relies on human-machine learning experts to perform the following tasks:
Pre-process and clean the data
Select and construct appropriate features
Select an appropriate model family
Optimize model hyperparameters
Postprocess machine learning models
Critically analyze the results obtained
As the complexity of these tasks is often beyond non-ML-experts, the rapid growth of machine learning applications has created a demand for off-the-shelf machine learning methods that can be used easily and without expert knowledge. We call the resulting research area that targets progressive automation of machine learning AutoML.
Natural Language Query (NLQ): A query expressed by typing English, French or any other spoken language in a normal manner. For example, “how many sales reps sold more than a million dollars in any eastern state in January?” In order to allow for spoken queries, both a voice recognition system and natural language query software are required.
Natural Language Generation (NLG): is a software process that transforms structured data into natural language. It can be used to produce long-form content for organizations to automate custom reports, as well as produce custom content for a web or mobile application. It can also be used to generate short blurbs of text in interactive conversations (a chatbot) which might even be read out by a text-to-speech system.
Conversational GUIs: are graphical user interfaces that include things such as natural language query (NLQ) and natural language generation (NLG) and Chatbot-like features.
Integration with Third-party Analytics Platform: Provides the ability to Integrate with Third-party analytics platform as a key BI fabric capability
Integration with Packaged DS & ML Solutions: Provides the ability to Integrate with packaged DS & ML solutions such as fraud detection, failure prediction and anomaly detection
Citizen Data Scientists Advanced Analytics: Enables users to easily access advanced analytics capabilities that are self-contained within the platform, through menu-driven options or through the import and integration of externally developed models.
Image & Video Analytics: Image & Video analytics are the automatic algorithmic extraction and logical analysis of information found in images and videos through digital image and video processing techniques.
Algorithm Engines and Libraries: Algorithm and analytics modeling workbenches are becoming an important capability for enterprises. These sets of tools create and then run the algorithms used in all parts of the enterprise (e.g., customer offer engines, fraud detection engines, and predictive maintenance). The D&A platform may also provide libraries for algorithms (e.g. machine learning algorithms).
Programming Languages & Notebooks: Provides the ability to use programming languages such as Open-source Python and R. Programming environments for data analysis such as R and Python provide open-source notebooks such as R Markdown or Jupyter which combine the analysis and the reporting.
ML Model Management: provides the ability to develop, test, monitor, maintain, deploy, and tune the ML models.
Mobile Exploration & Authoring: Enables organizations to develop and deliver content to mobile devices in a publishing and/or interactive mode, and takes advantage of mobile devices’ native capabilities, such as touchscreen, camera and location awareness.
Streaming Analytics: Provide the ability to capture and analyze high-velocity data as it “streams” through the system.
Geospatial Analytics: Geospatial analysis uses geospatial data to build maps, graphs, statistics, and cartograms, making complex relationships understandable. Representations like these can reveal historical shifts, as well as those that are underway today. They can even point to those that are likely to occur in the future.
Advanced-Data Visualization: Provides the ability to implement features such as animated visualization, dynamic data visualization, multidimensional visualization, visual exploration, and advanced interaction modes
Analytics Dashboards: Provides the ability to implement analytical dashboards. An Analytics dashboard is a collection of widgets that work together to tell a data story from multiple angles. Depending on what we want the dashboard to show or how to behave, different widgets can be added, such as key performance indicators, charts, tables, filters, and images.
Textual Disambiguation: Can be used to turn textual data into a structured format and maintain the unstructured flavour of the data. It is the role of textual disambiguation to ingest raw, unstructured text and to transform the important parts of unstructured text into a structured format while maintaining the essence of the unstructured data.
Business Process Analytics: Provide the ability to report on and analyze data and the state of business processes. This includes real-time information about process execution, such as throughput, service-level agreements, and backlog or patterns of incomplete documentation from any business process.
Traditional Query & Reporting: Provide the ability to perform ad hoc and predefined queries as well as the ability to generate analytical and operational reports from the different types of data sources
OLAP: Online Analytical Processing
Scorecards: Provide the ability to implement analytical scorecards including capabilities such as strategy maps, performance management scorecards (e.g. six sigma and balanced scorecards), data visualization, collaboration, and root cause analysis.
Write-back & Control Actions: The write-back capability allows users to write back to source applications, such as updating customer contact information. Control capability enables the user to control physical objects (things), typically through connected IoT or OT control devices.
Workflow and Collaboration: Provide the ability for users with different skills to work together on the same workflows and projects
IMDBMS & In-Memory Computing: An in-memory database management system (IMDBMS) is a database management system that predominantly relies on main memory for data storage, management, and manipulation. This eliminates the latency and overhead of hard disk storage and reduces the instruction set that is required to access data. To enable more efficient storage and access, the data may be stored in a compressed format [19]. In-memory computing (IMC) is a computing style where applications assume all the data required for processing is located in the main memory of their computing environment.
Administration, Governance and Security: Enable the administration, governance, and security of the analytic capabilities, analytic applications, and delivery ABBs of the D&A platform.
The Analytic Applications Layer
Business Intelligence: BI application is a package of BI capabilities for a particular domain or business problem. BI is an umbrella term that spans the people, processes, and applications/tools to organize information, enable access to it, and analyze it to improve decisions and manage performance.
Continuous Intelligence: Provides the ability to implement continuous. Continuous intelligence is a design pattern in which real-time analytics are integrated within a business operation, processing current and historical data to prescribe actions in response to events. It provides decision automation or decision support. Continuous intelligence leverages multiple technologies such as augmented analytics, event stream processing, optimization, business rule management, and ML.
Decision Intelligence: This type of application supports decision intelligence. Decision intelligence is a practical domain framing a wide range of decision-making techniques bringing multiple traditional and advanced disciplines together to design, model, align, execute, monitor, and tune decision models and processes. Those disciplines include decision management (including advanced nondeterministic techniques such as agent-based systems) and decision support as well as techniques such as descriptive, diagnostics, and predictive analytics.
Big Data Analytics: This type of application applies advanced analytics on big data sets in innovative ways to create one of the most profound trends in BI today
Other DS, ML& AI Enabled Applications: These types of applications include features such as:
Explainable AI: Explainable AI (XAI) is an emerging field in machine learning that aims to address how black box decisions of AI systems are made. This area inspects and tries to understand the steps and models involved in making decisions. XAI is thus expected by most of the owners, operators, and users to answer some hot questions like: Why did the AI system make a specific prediction or decision? Why didn’t the AI system do something else? When did the AI system succeed and when did it fail? When do AI systems give enough confidence in the decision that can be trusted, and how can the AI system correct errors that arise?
Conversational analytics: This feature will change how users interact with data. What is currently mainly a matter of dragging and dropping elements on a page becomes more of a natural language process involving voice conversations. By providing both a query mechanism and interpretation of results, conversational analytics represents the convergence of a number of technologies, including personal digital assistants, mobile, bots, and ML.
Graph enabled adaptive data science: This feature uses graph databases for analytics. Graph databases ultimately enable more complex and adaptive data science in the enterprise. The massive growth of these graphs is thus reportedly due to the need to ask complex questions across complex data, which is not always practical or even possible at scale using SQL queries.
Augmented Analytics: This feature leverages ML/AI techniques to transform how analytics content is developed, consumed, and shared. It automates data preparation, insight discovery, and sharing. It also automates data science and ML model development, management, and deployment.
API: Application programming interface such as REST Web Services APIs
Data Marketplaces /Datastores: Data marketplaces facilitate data transactions between data sellers (aka vendors or providers) and data buyers. They usually take a commission fee on each transaction and are either focused on a specific industry and/or data type. In recent years, a growing number of decentralized data marketplaces have emerged, with the goal to cutting out the middleman and directly connecting sellers and vendors.
Web Portal: is a specially designed website that brings information from diverse sources, like emails, online forums and search engines, together in a uniform way.
Unified Communications & Collaboration: Unified communications and collaboration (UCC) describes the combination of communications and collaboration technologies. Until recently, enterprise collaboration vendors were fairly distinct from those for enterprise communications, with software companies like Microsoft and IBM dominating the former and telephony and networking vendors comprising the latter. However, this distinction has become blurred because Microsoft and IBM offer voice and telephony features and vendors like Cisco have moved into the collaboration market.
PUB/SUB: In software architecture, publish-subscribe is a messaging pattern where senders of messages, called publishers, do not program the messages to be sent directly to specific receivers, called subscribers, but instead categorize published messages into classes without knowledge of which subscribers if any, there may be. Similarly, subscribers express interest in one or more classes and only receive messages that are of interest, without knowledge of which publishers, if any, there are. Publish–subscribe is a sibling of the message queue paradigm and is typically one part of a larger message-oriented middleware system. Most messaging systems support both the pub/sub and message queue models in their API, e.g. Java Message Service (JMS). This pattern provides greater network scalability and more dynamic network topology, with a resulting decreased flexibility to modify the publisher and the structure of the published data.
Voice Portal (ASR & TTS): Voice portals are the voice equivalent of web portals, giving access to information through spoken commands and voice responses. Ideally, a voice portal could be an access point for any type of information, services, or transactions. With the emergence of conversational assistants such as Apple’s Siri, Amazon Alexa, Google Assistant, Microsoft Cortana, and Samsung’s Bixby, Voice Portals can now be accessed through mobile devices and Far-Field voice smart speakers such as the Amazon Echo and Google Home [13]. IVR is interactive voice response and TTS is Text to speech conversion.
Streaming: see streaming analytics above
Mobile App: A mobile application, also referred to as a mobile app or simply an app, is a computer program or software application designed to run on a mobile device such as a phone, tablet, or watch. Apps were originally intended for productivity assistance such as email, calendar, and contact databases, but the public demand for apps caused rapid expansion into other areas such as mobile games, factory automation, GPS and location-based services, order-tracking, and ticket purchases so that there are now millions of apps available. Apps are generally downloaded from application distribution platforms that are operated by the owner of the mobile operating system, such as the App Store (iOS) or Google Play Store. Some apps are free, and others have a price, with the profit being split between the application’s creator and the distribution platform.
Write-Back & Control Actions: See Write-Back & Control Actions above
E-mail & SMS: Electronic mail and short message service
Office Applications: Productivity software suites including Word processor, Spreadsheet and Presentation program
Managed File Transfer: refers to a software or a service that manages the secure transfer of data from one computer to another through a network (e.g., the Internet). MFT software is marketed to corporate enterprises as an alternative to using ad-hoc file transfer solutions, such as FTP, HTTP, and others.
It is worth mentioning that the deployment model(s) of the digital business platform technology building blocks (including the D&A platform architectural building blocks) may take the form of on-premises, public cloud(s), private cloud (or community cloud), hybrid cloud, edge computing or even might be deployed on embedded systems. Each ABB may be deployed using any of these deployment models. Edge computing is a distributed computing paradigm that brings computation and data storage closer to the location where it is needed, to improve response times and save bandwidth.
Last but not least, it is worth noting that in the above-mentioned reference architecture, the technical capabilities of the D&A platform are considered as a shared D&A infrastructure that can be used to support the data management processes and the analytical applications that may run on any of the five platforms which make up the digital business platform.
Conclusion
The modern D&A platform reference architecture includes four main architectural building blocks, namely, the data fabric, the analytics capabilities, the analytics applications, and the delivery. The main difference between traditional D&A architecture and the modern D&A platform is that the modern D&A platform should be built on services-based principles and architecture. The data fabric layer of the modern D&A platform supports algorithm and analytics modeling workbenches. The data fabric’s automated/augmented data management capabilities automate the other capabilities of the fabric by leveraging AI & ML. Other differences include the use of data hubs, data products & data marketplaces, intensive use of semantic frameworks, active/passive metadata, graph DB & textual disambiguation. Similar differences also exist in the other 3 layers. Parts 3 and 4 of this series will explain how the reference architectures that have been explained in parts 1 and 2 can be used (together with the business strategy) to modernize a traditional D&A platform.
){kind=link}