
Reducing total cost of ownership (TCO) is a topic familiar to all enterprise executives and stakeholders. Here, I discuss optimization strategies in the context of AI adoption. Whether you build in-house solutions, or purchase products from AI vendors. The focus is on LLM products, featuring new trends in Enterprise AI to boost ROI. Besides the technological aspects, I also discuss the human aspects.
What is TCO
Total cost of ownership spreads across multiple layers where ROI leaks may occur. The main cost drivers are
- Acquisition, implementation and installation: Initial purchase of hardware and software. Installation, configuration, and integration with existing systems. Data centers, electricity usage, and network resources.
- Operations, maintenance and support: Ongoing expenses such as software subscriptions, licensing, and cloud computing resources (e.g., compute time, model training, storage, GPU, API calls). Costs for updates, patches, technical support, and labor (contractors, employees).
- Security, and human: Downtime, performance inefficiencies. Employee productivity loss, compliance risks. Hallucinations and data leaks. Learning curve, onboarding process.
Earlier examples of cost optimization
I started my career as a BI analyst, albeit one with engineering and development skills that allowed me to automate my job more than 20 years ago. To this day, many employees still manually perform the tasks that I optimized long ago.
- I was once hired to build a list of the top 100k commercial keywords. I found a Google API that did just that, at a fraction of the salary I was paid for. The company quickly started to use the API, and I moved on different projects.
- I trained BI analysts to use my Python scripts for DB queries, rather than dashboards, speeding up data extraction by a factor 10. It required very good relationship between marketing and the IT team who also trusted me, to make it happen.
- I automated my BI tasks: extraction, cleaning, data analysis, emails sent weekly to stakeholders with most important info summarized in a concise and visual way. What happened here is that the company hired a BI manager (me) who also happened to have decent engineering skills and good connections with the IT team. My boss knew that I barely worked, but he never fired me.
In practice, few employees will tell their boss that they found a way to work only one hour per day while delivering above expectations. To identify these inefficiencies, you may hire an external consultant. More recently, while working on tabular synthetic data generation, I found a way to do it better, faster, without deep neural networks. And I also came up with much more robust evaluation metrics. If you only hire employees who have strong experience with the standard tools, they are likely to implement what they know. Innovation does not really happen.
The Human Factor
These are related to the hiring process, general executive mindset across many organizations, and marketing influence. In US, bigger is better. The tendency is to throw more money at it when facing an issue. We need a mindset shift, get the CFO involved. And shift to doing better with less. See my article “Doing better with less: LLM 2.0 for enterprise”, here. Other barriers include:
Cultural issue: Career growth linked to how many employees report to you and the size of your budget. Slowly but surely, some competitors are adopting a lean approach (my case, with startup burn rate 7x below peers.)
Investor pressure: Investors and executives need to be better educated about AI alternatives and not always react to emergencies (“we need AI right now, whatever is available”). Changes in VC environment, with LPs wanting to eliminate the middleman, may bring learner startups in the near future, a positive shift.
Marketing influence: Transformer model encroachment. Big companies offering $200k of free GPU for 2 years, to startups. After the free period, you must pay, thus charge your customers accordingly. Other factors: hiring focused on people who have learned/used the exact same models. Colleges and textbooks teaching the same material, slow to respond to change. Independent research done outside academia or Google labs now getting traction.
Hiring in the age of AI. Here is some food for thoughts:
- Companies want to hire very expensive OpenAI engineers. Don’t. Build the future, not the past.
- Great candidates outside US. But reluctance to have overseas employees. Looking for H1-B when best candidates prefer to work from their home country (no visa, saving time and money). How to do it? Ask me or AI. Use AI to recruit.
- Hire well-known advocate to attract talent. Offer employees to spend 10% of their time on sexy projects besides mundane tasks (your bread and butter). In my case: predicting heart attacks, DNN watermarking.
- Einstein was a clerk tasked to get all railway stations in Switzerland to show the exact same time. Relativity theory was born out of it. Kitchen chef impressed me with how he could use AI to solve problems he knew nothing about. Impressed by my 18-year-old son too. Ask candidates to use AI in job interviews.
Examples of inefficiencies
AI is still in its infancy. As an analogy, in 2000 Google charged by the click resulting in trillions of garbage clicks. Now publishers charge based on performance. In 2025: AI companies charge by token usage. Lots of garbage tokens (partly due to the way DNNs work). We are shifting to performance-based models. At BondingAI, that’s what we offer. We have no incentive to create tons of garbage tokens to make more money. Here are specific examples of inefficiencies:
- Siloed databases: Your Enterprise LLM fails to answer basic questions because it is not connected to some sources. Some sources can be external. When implementing AI solutions, you need to work with internal experts familiar with where all the important information is located, to not miss critical pieces in your puzzle.
- Poor QA: Generate synthetic prompts for testing. Include exhaustivity in your evaluation metrics. Take user feedback into account: “this answer is useless” (time and over) helps discover missing parts and fix it. Possibly by augmenting your corpus or integrating extra data sources.
- Common sense: Do you need a model with 40B parameters when your corpus has much less than 1M tokens? Human beings know about 30,000 English words. If you use a lot more than that in your chat response, it will be incomprehensible. Also linked to resistance to change and old beliefs (you need 40B tokens).
- Not properly leveraging AI: Learn how to get AI to respond in layman’s terms. Rather than complaining of buggy code generated by AI, find the issues and ask AI to fix them.
Key Elements for Optimization
Here I describe key elements of our AI architecture, to boost efficiency. If you build a home-made solution or choose a vendor or combine multiple solutions, the following are key points to consider.
First, we use a mixed RAG/SLM. The structured output is the base response to a prompt. It consists of summary cards with tags, links, relevancy and trustworthiness scores, as well as other contextual elements and related queries. It is the RAG layer below the classic text response in the figure below. This output is very compact, thanks to relevancy scores discarding poor information, the focus exclusively on your corpus or authorized sources, and distillation. It minimizes the risk of hallucination and eliminates the need for prompt engineering. Also, it provides very accurate links or references. Some call it small language model (SLM), we call it specialized language model.
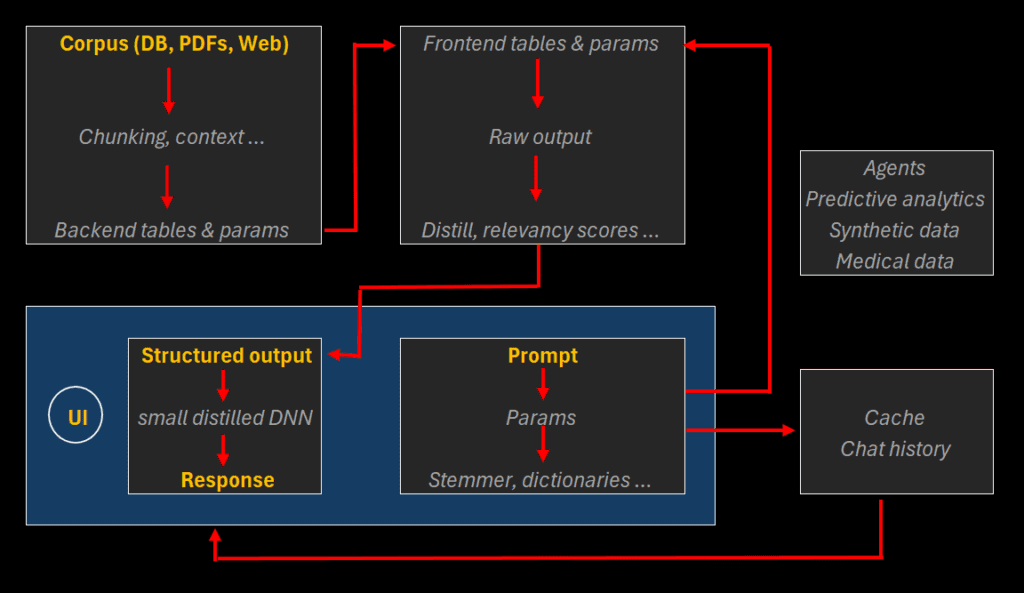
We use small DNNs (deep neural networks) with distillation, based on the structured output, to generate (if needed) the standard response. The full corpus is typically < 1 million multi-tokens. In previous tests, reducing the training set size by 80% did not result in perceptible loss of accuracy.
Also, we don’t need GPU, and there is no expensive training, no Blackbox. Thus, resulting in low electricity consumption and low cost. No external API calls, increasing the security. On-premises implementation if required by client. Fast onboarding and learning curve, easy to plug APIs from client or other vendors. We even offer in-memory RAG with real-time fine-tune thanks to the massive reduction in parameters. Other important features include:
- Cache optimization: too much is not good, can be costly if on GPU. Cache can grow unmonitored. We also minimize memory leaks that clog the system over time. Switch between CPU and GPU as needed.
- Documentation with index, glossary, tags, and code explanation with examples; meaningful variable names and conventions, versioning. Use our own xLLM to retrieve information from our large documentation repository!
- Table redundancy to accelerate retrieval. Building mappings and reverse mappings, for instance: parent-to-children chunk mapping, and reverse; original keyword (multi-token) to stemmed version, and reverse (un-stemmer); chunk ID mapped to tags or categories, and reverse.
- Reproducibility. Run same query twice in two sessions with same params, get same answer. Otherwise, hard to debug!
- Security & compliance: Results in liability and extra costs if poorly executed. We offer control access at the corpus and chunk level (authorized users). On-premises, no Blackbox, explainable AI. No call to external API, your data not exported. DNN/Data watermarking to protect against unauthorized use. We use your data only, and/or approved external sources. Also, we detect issues in your data by looking at response scores; we fix them. Exact retrieval possible to reduce liabilities, e.g. when dealing with legal documents.
- Better Evaluation and Benchmarking. See my article “Benchmarking xLLM and Specialized Language Models: New Approach & Results”, here.
- Optimized algorithms. For instance, O(n2) replaced by O(n) when possible. Example: to create the sparse keyword correlation table based on keyword proximity within a chunk.
- Quantization. 4 bits rather than 32, combined with fast approximate nearest neighbor search.
For more information, contact the author. See also our presentation on the topic, here, and recording of live session available here.
About the Author

Vincent Granville is a pioneering GenAI scientist, co-founder at BondingAI.io, the LLM 2.0 platform for hallucination-free, secure, in-house, lightning-fast Enterprise AI at scale with zero weight and no GPU. He is also author (Elsevier, Wiley), publisher, and successful entrepreneur with multi-million-dollar exit. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. He completed a post-doc in computational statistics at University of Cambridge.