
Standard LLMs rely on prompt engineering to fix problems (hallucinations, poor response, missing information) that come from issues in the backend architecture. If the backend (corpus processing) is properly built from the ground up, it is possible to offer a full, comprehensive answer to a meaningful prompt, without the need for multiple prompts, rewording your query, having to go through a chat session, or prompt engineering. In this article, I explain how to do it, focusing on enterprise corpuses. The strategy relies on four principles:
- Exact and augmented retrieval
- Showing full context in the response
- Enhanced UI with option menu
- Structured response as opposed to long text
I now explain these principles. To design hallucination-free LLMs, see this article.
Exact and augmented retrieval
Breaking down the corpus into sub-LLMs governed by an LLM router is the first step. DeepSeek calls it “mixture of experts”. Hierarchical chunking, with small and larger chunks, further increases the granularity. It allows you to match elements of the prompts to very precise portions of the corpus. You can then provide highly targeted links to the source, in the response. By contrast, many LLMs provide loose links that don’t contain the exact information the response is based on.
The problem is more acute if the response consists of long text with significant rewording, with each sentence blending concepts or information coming from different parts of the corpus. It reduces accuracy and generates hallucinations.
To provide exhaustive results, augment the prompt with an acronym and synonym dictionary to link keyword combinations in the prompt, to corpus lingo which may use a different wording. We also use proprietary un-stemming technology for this purpose. For instance, say “games” is in the prompt. It gets stemmed to “game”, and then un-stemmed to {“games”, “gamer”, “gamers”, “gaming”} and so on, assuming these are in the corpus. In addition to looking for “games”, we also look at all its variations in the un-stemmed list. Variations that are not an exact match in the prompt, get a lower weight.
Showing full context in the response
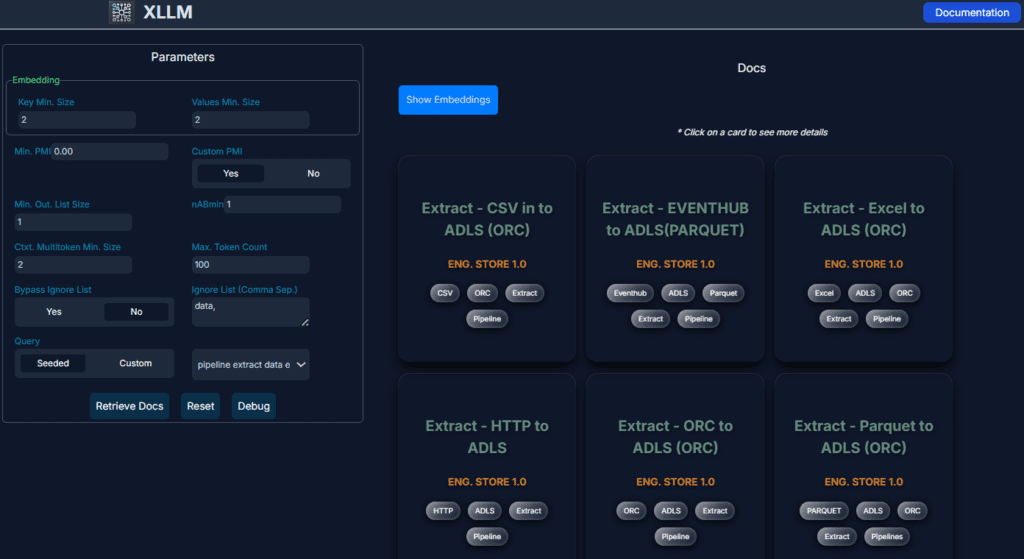
In Figure 1, the response consists of 6 cards. Each one corresponds to a chunk or sub-chunk in the corpus. A card summarizes retrieved information matching elements found in the prompt. It displays the contextual fields attached to the parent chunk: category, title, document title, date, chunk size, link to source, links to images or tables, tags, parent category, subcategories, and so on. Click on the card of your choice to get the full information.
The number and names of contextual fields may vary from chunk to chunk. They come from the corpus taxonomy and knowledge graph detected while crawling. However, some are generated post-crawling with a labeling algorithm.
In short, choosing and clicking on a card is the equivalent of a second prompt in standard LLMs. The main difference: cards contain information in the corpus, while a second prompt may still be asking for information not in the corpus.
Enhanced UI with option menu
Rather than guessing the user intent, you can deliver a better response by allowing the user to choose options: selecting a category, sub-LLMs he is authorized to access, tags, agents, and so on. In Figure 1, the left panel allows the user to fine-tune the response in real time, via intuitive parameters (explainable AI). There is even a debugging mode and pre-seeded prompts.
In the prompt box, you can enter negative keywords, do broad or exact search, put more weight on the first prompt multi-token, or search by recency. Also, each card displays a relevancy score based on our proprietary E-PMI metric. If xLLM (the name of our product) does not have a good answer, it shows on the card. It does not make up stuff when it has no good answer.
Finally, the blue embeddings box lists related keywords and prompts corresponding to information that exists in the corpus. In one-click, you can run your next prompts if you need to, knowing it will come back with a meaningful response.
Conclusions
I explained how to generate the raw response, the one that does not need prompt engineering, and free of hallucinations. Another version (instead of cards) consists of showing different sections (categories, links, related items) each with a bullet list, and a relevancy score attached to each item. Or the response can be organized by multi-tokens found both in the prompt and (via acronyms, synonyms, un-stemming) directly or indirectly in the corpus. It can also be organized by tags (pre-made or detected in the corpus).
A multi-token is a combination of words found in the prompt and in the corpus. If a prompt consists of 10 words (after cleaning), we look at all combinations, augmented with synonyms and so on, to see those found in the corpus. We do so very fast by using nested hashes and sorted / unsorted n-grams, without vector database or standard embeddings. In the end, while we do not use transformers, neural networks or GPU, the apparent simplicity of our system is an illusion. The complexity is buried in the number of components — many new to our technology — and how they are jointly optimized and synchronized.
To produce a “long text” answer typical of other LLMs, you need an additional layer to complement the architecture. You can do it with small specialized deep neural networks that you train from scratch, not pre-trained models where 99% of the tokens are irrelevant to specific business contexts. Highly distilled pre-trained models are another option. But the user should be allowed to choose between the concise structured output in Figure 1 (no hallucination, very efficient, low cost), or “long text” for the response. To learn more about our architecture, read my most recent articles, here.
About the Author

Vincent Granville is a pioneering GenAI scientist, co-founder at BondingAI.io, the LLM 2.0 platform for hallucination-free, secure, in-house, lightning-fast Enterprise AI at scale with zero weight and no GPU. He is also author (Elsevier, Wiley), publisher, and successful entrepreneur with multi-million-dollar exit. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. He completed a post-doc in computational statistics at University of Cambridge.
{kind=link}
Vincent,
Enjoyed reading this post and have been a longtime follower. I have been exploring the various issues in prompt engineering. Will your algorithm address the need when one has to research further such as Root Cause Analysis or answering the Five “Why” Question when critical thinking is needed?