

Two roads diverged in a wood, and I;
— Robert Frost
I took the one less traveled by,
And that has made all the difference.
At certain points in the evolution of enterprise artificial intelligence, there’s been a fork in the road. The road less traveled has suggested a different route to a more satisfying kind of success. That success will be more beneficial over the long term, but is harder and more time consuming to achieve.
Unfortunately, most AI media buzz dwells on the shortest path to some kind of tactical value. That’s the most traveled road. What happens as a result? Nagging problems like a lack of trustworthy inputs and outputs are a can that keeps getting kicked down the most traveled road.
The generative AI approach of large language models (LLMs) has been on the most traveled road of evolution. Now we’re facing another fork in the road: Retrieval Augmented Generation (RAG). RAG gives us another opportunity to address the trustworthy data challenge.
The most traveled road for RAG
According to Ben Lorica, ex-O’Reilly pundit and author of the Gradient Flow newsletter, “RAG refers to the process of supplementing an LLM with additional information retrieved from elsewhere to improve the model’s responses.”
That’s a helpful definition, one that leaves room for many different ways and means to effectively retrieve just the right information for the purpose at hand in order to augment (and thereby improve) what’s to be generated in terms of answers to pressing business questions.
Unfortunately, the most traveled road, given generative AI’s typically narrow, here’s-the-only-way-to-do-it focus, will have the characteristics of an AI data adhocracy:
- Project specific. The focus will be on the use case at hand. Applicability to other projects and disciplines will be secondary.
- LLM dedicated. The data improvement efforts will benefit the end user within the use case footprint of the LLM, but may not have a broader impact.
- Numerical only. RAG often relies only on vector embeddings for additional context, with the result that the generative AI’s logic capabilities will be solely numerical and therefore probabilistic. Claims that machines can “understand” with the help of these embeddings are overstated. Symbolic logic is necessary to complement the numerical for machine understanding.
FAIRification: The road less traveled
The best way to do RAG at scale would be what life sciences enterprises are currently doing with their FAIR (findable, accessible, interoperable and reusable) data initiatives to avoid reinventing the wheel.
FAIRification is a broad, organic approach to trusted data management, one dataset at a time. Each dataset worthy of reuse grows and evolves into a mature state. This diagram from Danielle Welter of the Luxembourg Centre for Systems Biomedicine, et al., outlines the process:
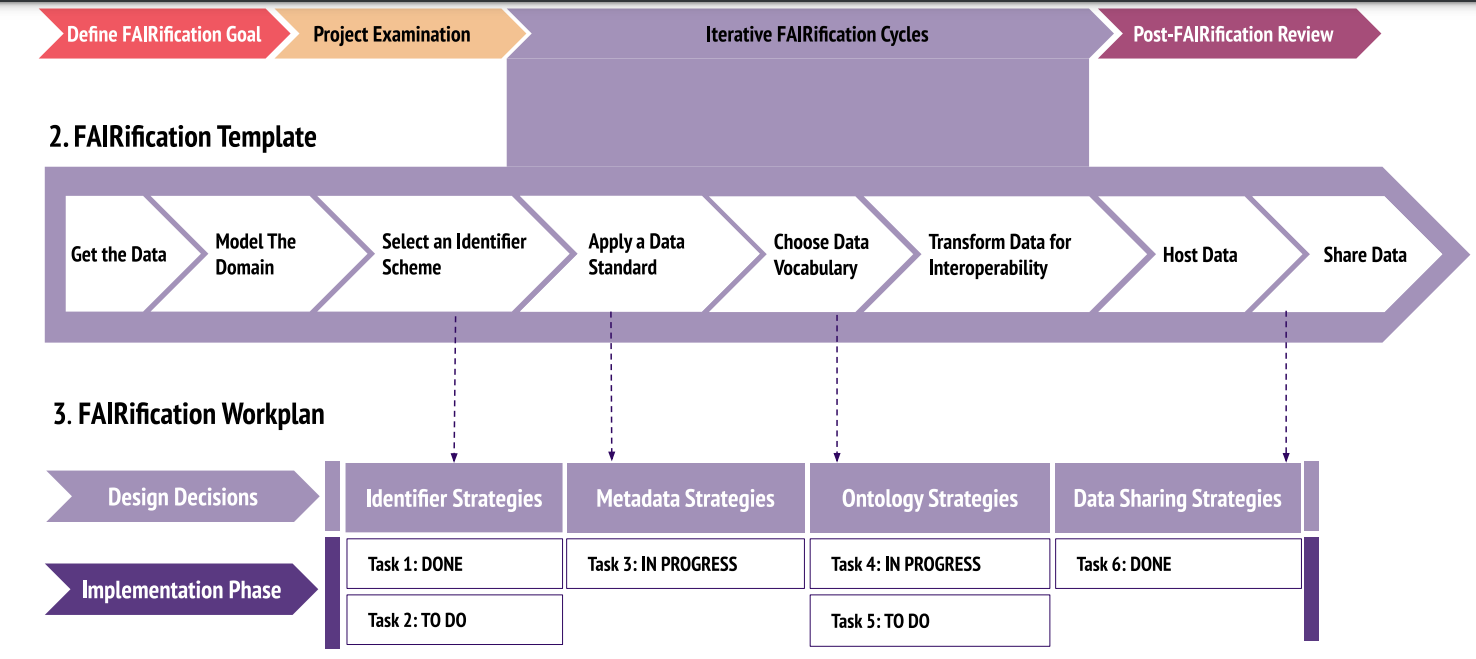
Welter, D., Juty, N., Rocca-Serra, P. et al. FAIR in action – a flexible framework to guide FAIRification. Sci Data 10, 291 (2023).
Then that dataset joins others in an accessible, managed environment designed for discoverability. So the same dataset could be reused in conjunction with others for many different purposes, from agent-managed digital twins, to LLMs, to humbler analytics uses. Moreover, the datasets are designed to be self-describing, so that subgraphs can be plugged into a larger, interoperable knowledge graph.
The focus is on quality, trustworthy, logically interconnected data first so that the effectiveness of the algorithm should benefit from high data quality to begin with. Life sciences companies have to put the long-term management and reuse of quality data high on the priority list, because they are asset tracking at the molecular level.
The striking contrast between FAIRification and data preparation by data scientists
In Lorica’s RAG diagram, the retrieval process starts with raw data sources and data preparation. Most AI projects start with an initial compromise: the available data in whatever shape it’s in. Data scientists often don’t have the opportunity to do more than the basics with data preparation.
As you can tell, FAIRification differs radically from what’s ordinarily done in most enterprises. Most cloud services, SaaS providers and IT departments still have not addressed the problems of siloing, fragmentation, hoarding, data duplication and logic sprawl.
Legacy data management determines the road most enterprise data scientists, architects and engineers travel by. The best way to improve model responses capitalizes on the most optimal means of managing heterogeneous data as scalable, contextualized knowledge, with rich graphs that are meaningfully connected because each subgraph expresses its own context in a standard way that contexts can be snapped together reliably.
{kind=link}