

Back in 2018, I had the privilege of keynoting at one of Semantic Web Company’s events in Vienna, as well as attending the full event. It was a great opportunity to immerse myself in the Central European perspective on the utility of Linked Open Data standards and how those standards were being applied. I got to meet innovators at enterprises making good use of Linked Open Vocabularies with the help of SWC’s PoolParty semantics platform, Ontotext’s GraphDB and Semiodesk’s semantic graph development acceleration software, for example.
There is so much that is impactful and powerful going on at these kinds of semantic technology events. So many people in the audience grasp the importance of a semantic layer to findable, accessible, interoperable, and reusable (FAIR) data, regardless of its origin and its original form–whether structured data, or document and multimedia content.
Fast forward to 2023, and it’s encouraging to see that more enterprises in the US have been latching onto these same approaches. One of the compelling case studies featured at this year’s PoolParty Summit on March 7th and 8th is Avalara’s.
Avalara is a sales and use tax automation software provider with more than 30,000 customers such as Netflix, Box, and 25 different US states. Avalara is focused on transforming how the right tax content, rule, and rate information the company maintains gets to the right users at the right time, in the right channels, its most useful and relevant form, which is why they’ve been using SWC’s and Ontotext’s approach to semantic content maturity.
Challenge: How to Deliver the Right Answers to Avalara’s Users
Tax compliance automation services imply the need to monitor and match specific requirements to the entities that must comply with those requirements. If you’re a merchant, how do you know which requirements apply to you with different buyers in different geographies, and how do you know when those requirements change? This sort of matching exercise is a huge task in a frequently changing regulatory environment and one that has historically demanded a substantial amount of manual work when it comes to:
- Sales tax registration
- Calculation
- Exemption certificate processing
- Returns preparation, filing, and remittance
- Notice management, and
- Audit support
Senior Director of Content Platforms Michael Iantosca at Avalara is responsible for what he calls Big Content at Avalara, which includes:
- Product documentation
- Product user support
- Partner documentation, and
- Enablement content
Among other essential data, Avalara maintains an extensive database with tax info, rules, and rates. The challenge is how to deliver what users need from its repositories when it comes to content.
“When you’re trying to extract just a table, a set of procedures or an answer to a chatbot query, or you’re trying to respond to a series of events in a software application, you want to give a granular experience, or combine granular experiences,” Iantosca says. “It’s best to start out if you can with componentized content: content objects.” With a Document Object Model (DOM) kind of content model, he says, smart applications can “understand” the hierarchy of components within the context of documents–even when those components are used in larger documents.
User-Centric Content
The other side of getting the right precision content to the right person at the right time in the right channel is to understand user needs and behavior. Gaining an informed perspective of sequences of events, where the user sits in the scheme of things and what they’re doing, is essential.
“I want to know what you’re doing at the moment you’re doing it,” Iantosca says. The goal is real-time assistance, or even anticipating what assistance is needed. Events or sequences of events help to trigger personalized responses from the system.
What all these efforts come down to is conveying a better understanding of the sources (the content) and the points of consumption (the users) in a way that machines and humans both contribute what they can to the solution. “How do you get from where you are to this wonderful world? It’s not something that you can throw an AI engine like IBM Watson at and make it work,” Iantosca concludes.
That type of content model makes it possible to deliver more precisely and reliably what a given user is asking for. Other, more monolithic approaches–including ChatGPT, Iantosca points out–can’t just pick out the specific components needed because that explicit contextual detail isn’t available in the corpus being used.
The Journey to a Knowledge Graph and Smarter AI
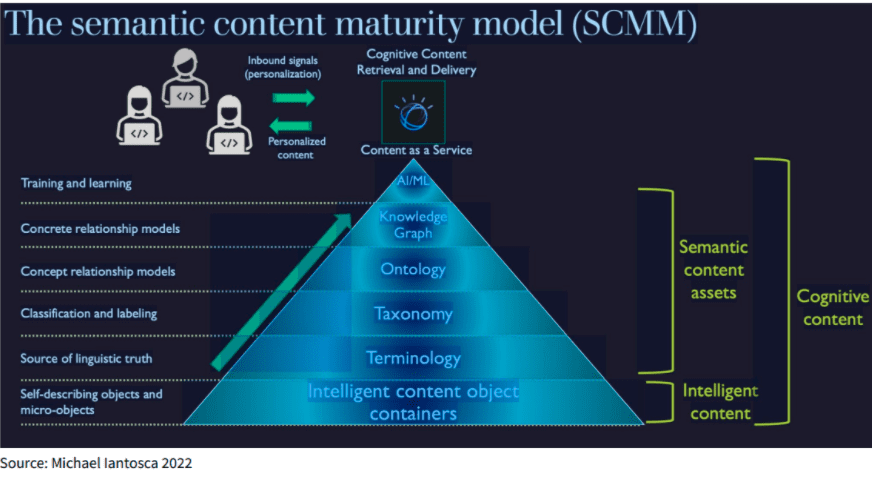
Iantosca also underscores how each step toward AI/ML in what he calls “The Semantic Content Maturity Model (SCMM) is essential.
Terminology: Besides smart content object containers, every company needs shared definitions of its own terms. Otherwise, “The rest of your solution is a house of cards.”
Taxonomy: “Taxonomies are your entities. They’re things.” Logically classifying entities “for your own particular world” with taxonomy-based auto labeling helps with faceted search, for example.
Ontology: “Ontology is simple,” Iantosca promises. “All you’re doing is creating a superclass structure to disambiguate all of those terms” contextually, so that a window is distinguished from Microsoft Windows, say. Companies always have more than one definition of the product. Ontologies disambiguate different definitions via the contexts they describe and connect.
Knowledge Graph: An ontology also provides the means for autogenerating a knowledge graph, Iantosca says. Big content requires an automated means for creating big knowledge graphs. A knowledge graph is a scalable content discovery, sharing, and interoperability medium, a semantic layer for every object it is connected to. KGs are useful for all kinds of data, not just content. And they’re both human and machine-readable, with a unified ontological model that abstracts and logically connects tiers of described business domains. Without ontologies, there is no FAIR content and no truly semantic search across dozens of disparate sources. Ontologies and KGs are how content, data, and knowledge management can scale.
{kind=link}