

The next task in your calendar, the ranking position of your favorite sport team in the league, the contact list in your cell phone, all of these have an order. Order matters when we process information. We use order to make sense of our lives and to optimize our decisions. Imagine looking for a word in a dictionary with a mixed alphabetical order, or trying to find the cheapest product in a disordered pricing list. We order stuff to make more sound decisions (which in reality is an illusion), and this makes us more confident on the results.
But there is a problem: the world is chaotic and inherently disordered (at least from our human perception). Today’s data is messy and excessive, which is a really bad combination. How can we order this massive information vortex in a way that makes sense to us? This is where computer sorting algorithms play a key role.
The Universe of Sorting Algorithms
In simple terms, an algorithm is a step by step method for solving a problem. Algorithms are based on taking an input and conducting a sequence of specified actions to reach a result. They are used in widely areas like computer programming, mathematics, and even our every day lives (e.g. a cooking recipe is an algorithm).
Algorithms exist far before the invention of computers , but since the explosion of modern technologies computer algorithms have expanded and replicated everywhere. Now, from the huge universe of computer algorithms, I think sorting algorithms deserve a special chapter.
Sorting algorithms are fundamental to computer science. They turn disordered data into data ordered by some criteria, such as alphabetical, highest-to-lowest value or shortest-to-longest distance.
They basically take lists of items as inputs, perform specific operations on those lists and deliver those items in an ordered manner as outputs. The many applications of sorting algorithms include organizing items by price on a retail website and determining the order of sites on a search engine results page
There are many different sorting algorithms out there, but one thing they share in common is that they are better understood when visualized. In the following examples, we take one disordered list and sort it with 5 different algorithms: Selection Sort, Insertion Sort, Bubble Sort, Merge Sort and Quick Sort. Let’s take a look.
Selection Sort
The Selection Sort algorithm is based on the idea of finding the minimum or maximum element in an unsorted list and then putting it in its correct position in a sorted fashion. In case of sorting in ascending order, the smallest element will be at first and in case of sorting in descending order, the largest element will be at the beginning.
So, when sorting in ascending order, Selection Sort works by repeatedly finding the minimum element from the unsorted part of the list and putting it at the beginning. In every iteration, the minimum element from the unsorted part of the list is picked, and moved to the sorted part of the list. In order to do this, the algorithm looks for the smallest value (in the case of ascending order) as it makes a pass and, after completing the pass, places it in the proper location.
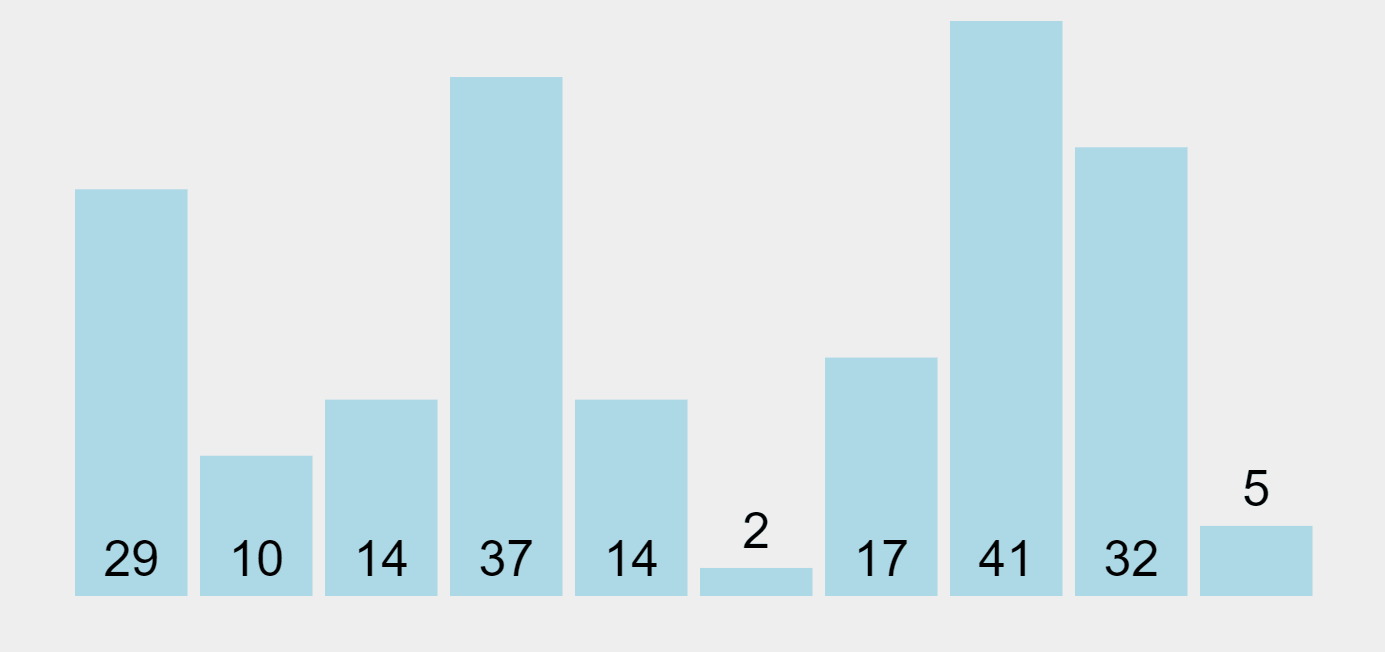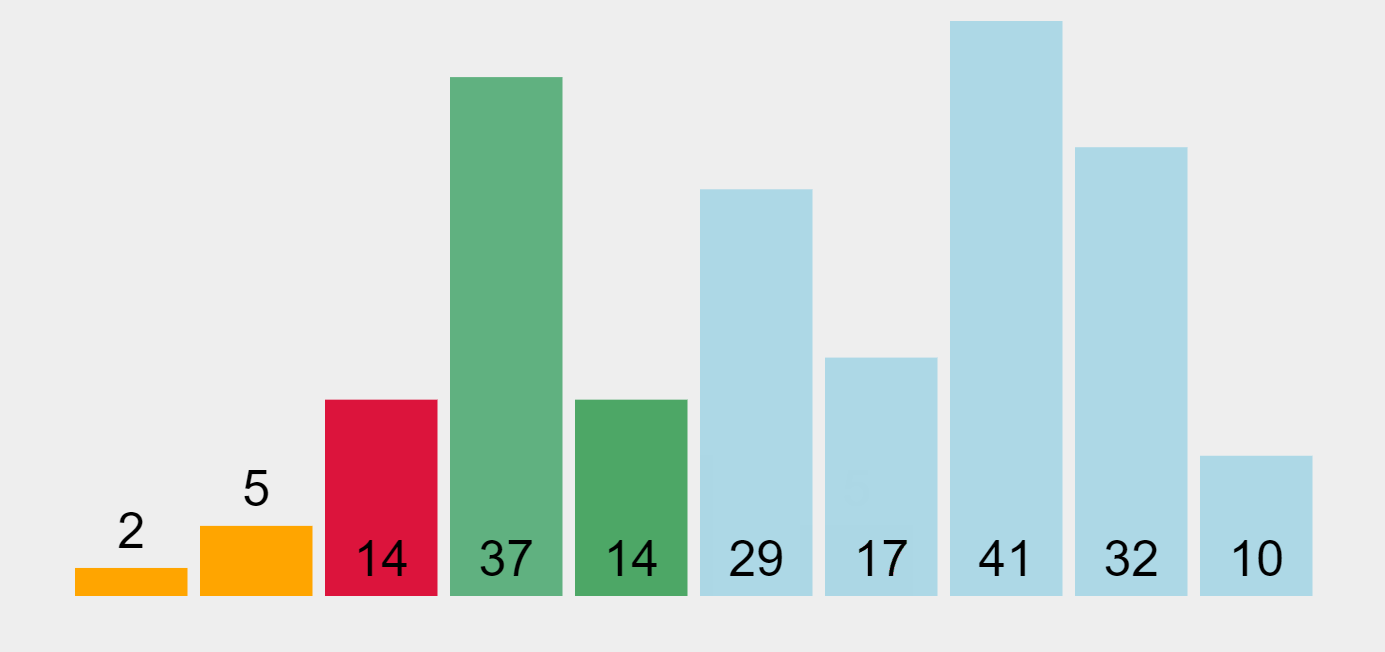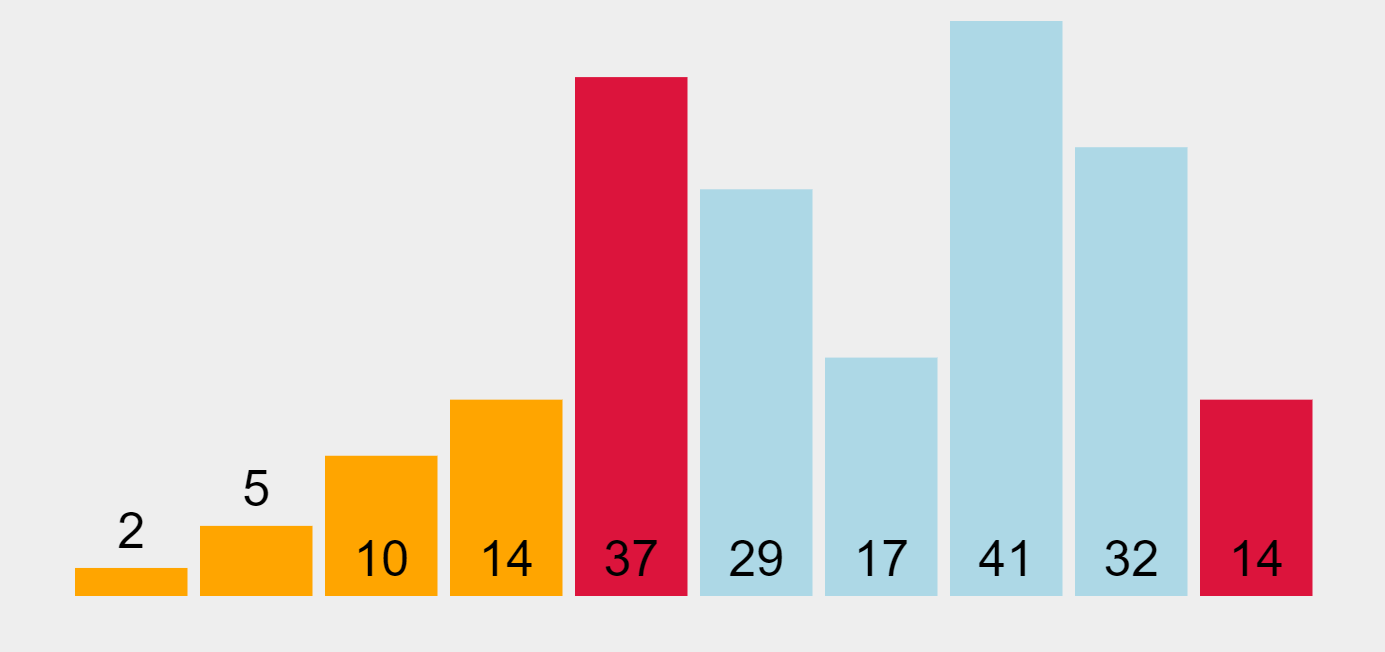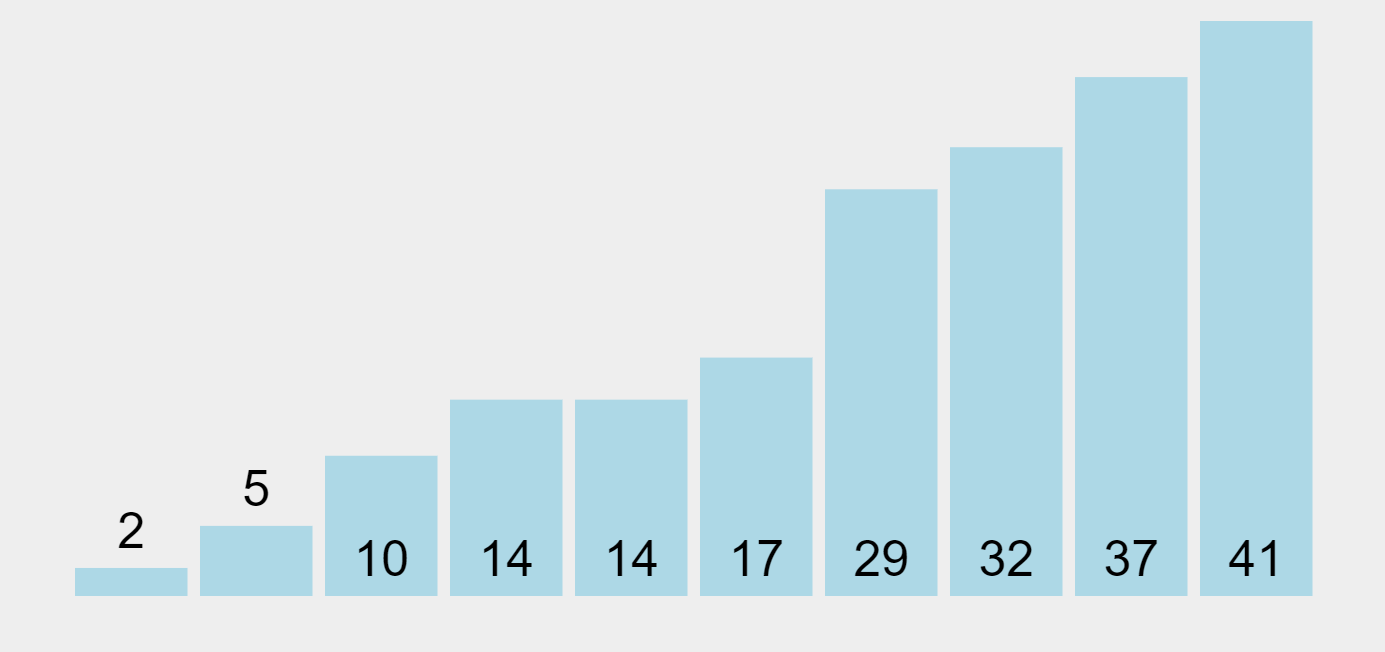
Selection Sort Algorithm (ascending order)
Look at the example above. The list that needs to be sorted in ascending order is divided into two parts, the sorted part at the left end and the unsorted part at the right end. Initially, the sorted part is empty and the unsorted part is the entire list. The smallest element (2 in this case) is selected (marked in magenta) from the unsorted list and swapped with the leftmost element, and that element becomes a part of the sorted array (now in orange). This process continues by moving unsorted elements one by one from the unsorted list to the sorted one, until no more elements are left.
Selection Sort is very intuitive, but since it needs to scan through the whole list to find the next small value, it can be quite slow when dealing with huge volumes of data.
Insertion Sort
Have you ever sorted playing cards in a game? If the answer is yes, then that’s Insertion Sorting.
Like in Selection Sort, Insertion Sort divides the elements in sorted and unsorted lists. In this algorithm, elements are searched sequentially and unsorted items are moved and inserted into the sorted list until all the unsorted values are covered.
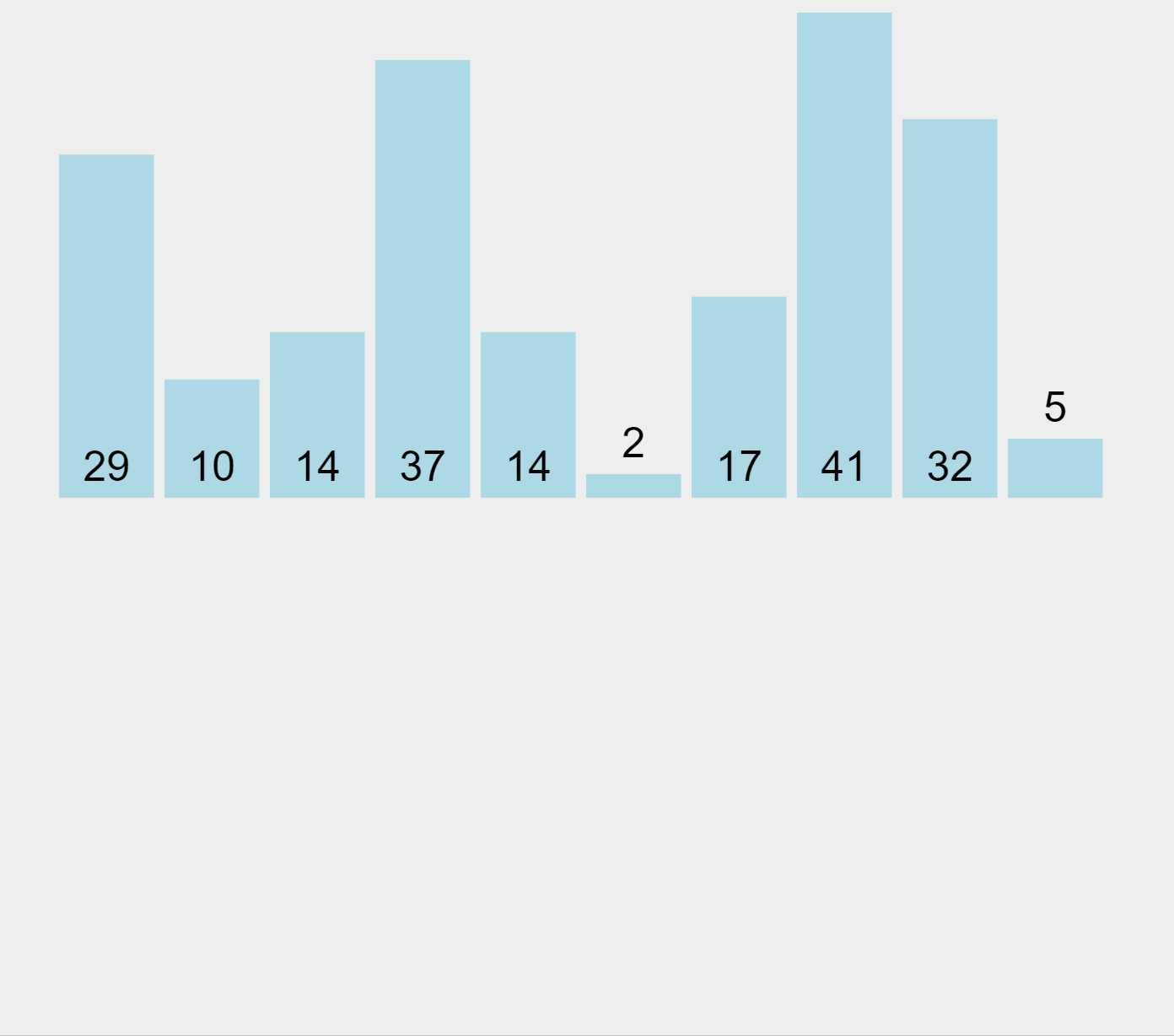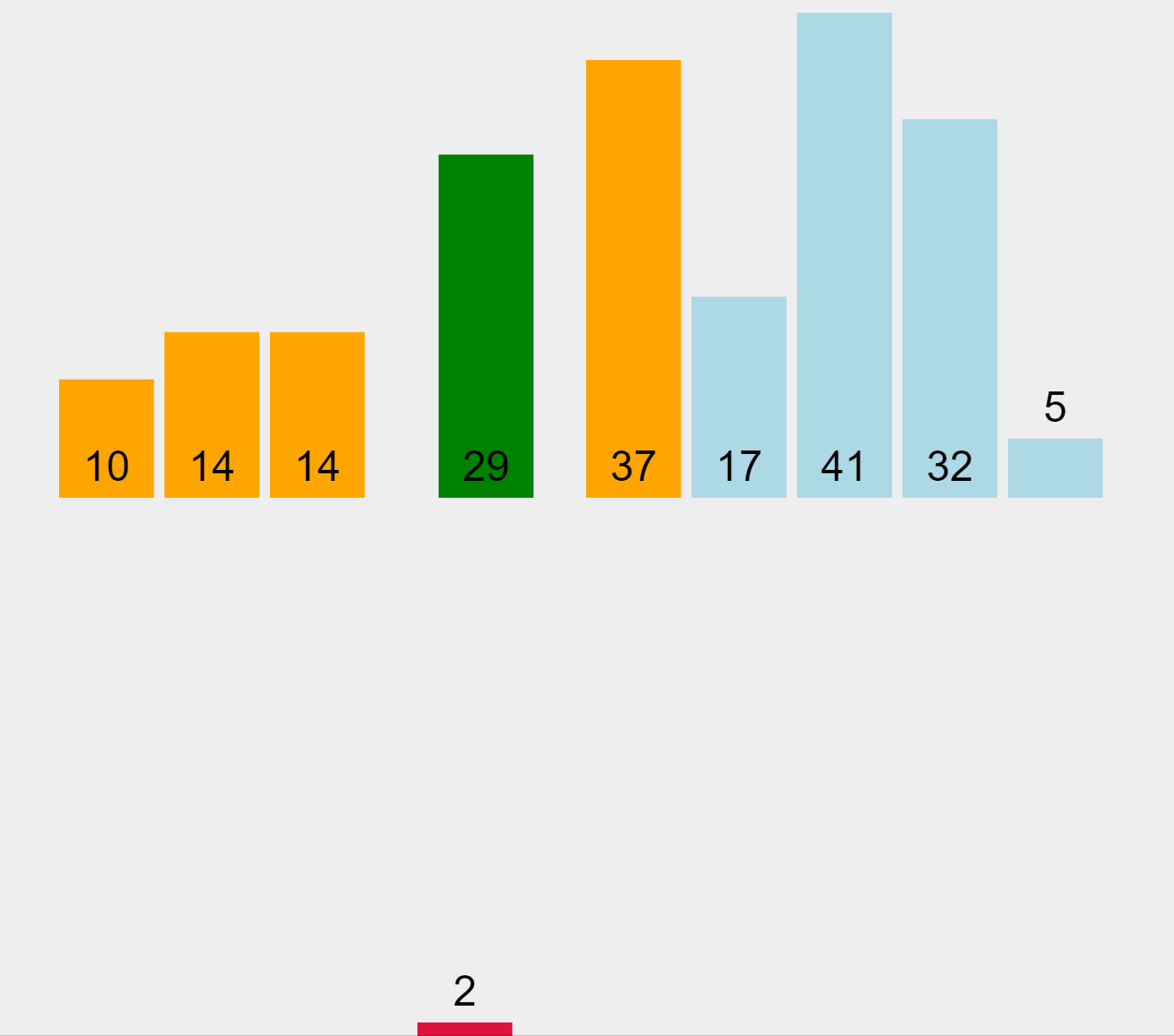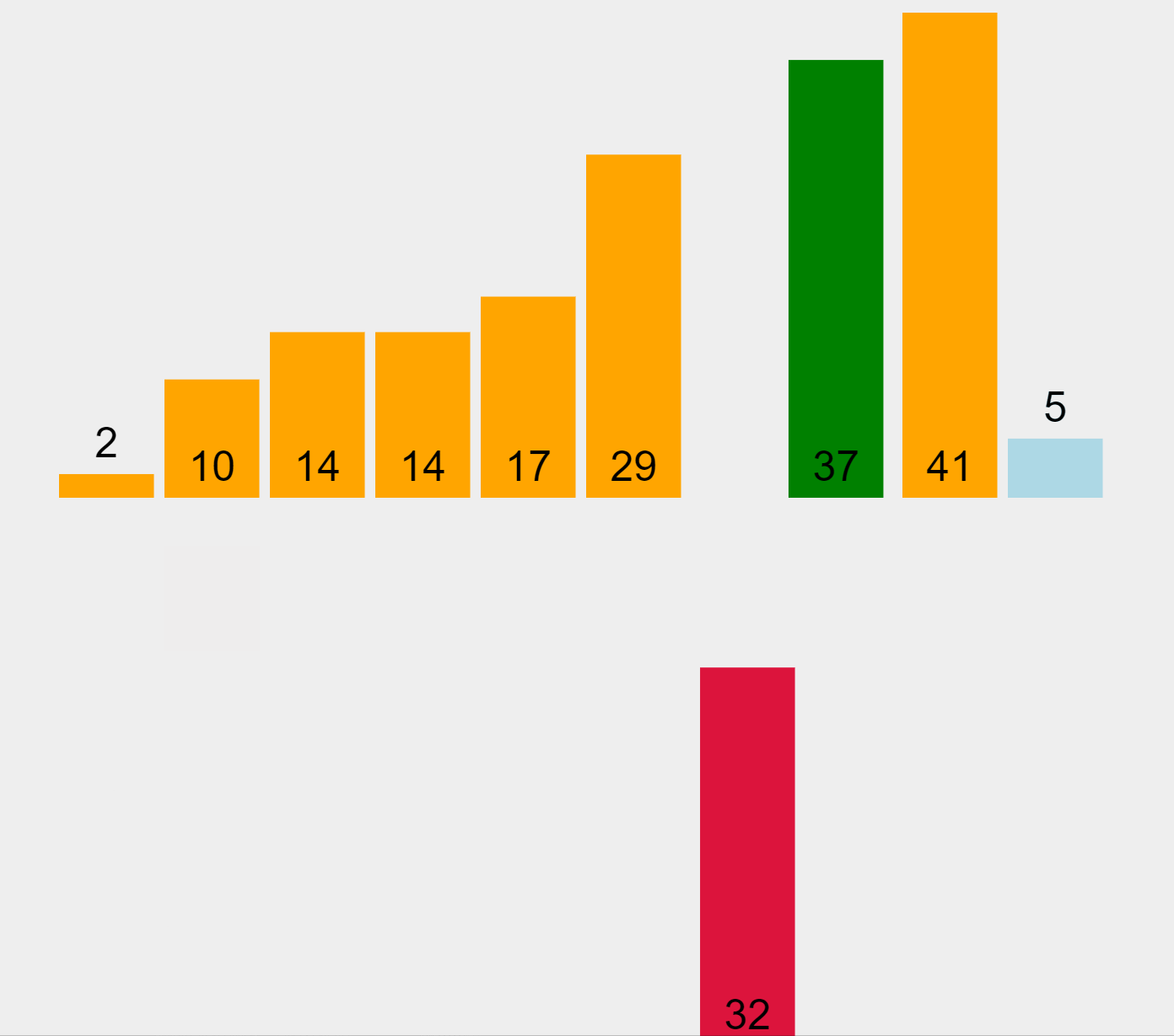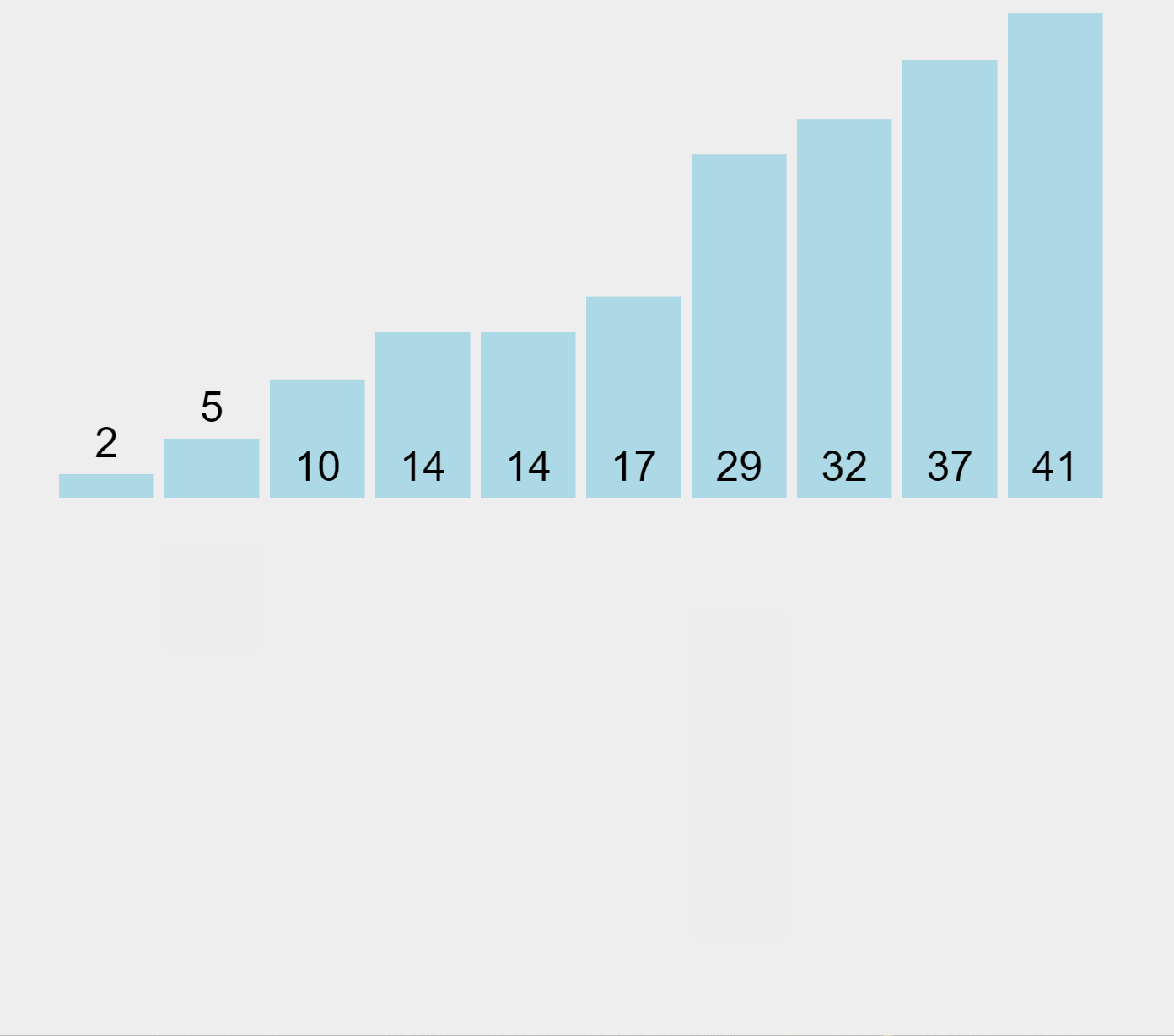
Insertion Sort Algorithm (ascending order)
In our example and starting from the left, the algorithm marks the first element (29) as sorted. Then it picks the second element (10) which is located in the unsorted list, and compares it with the previous one, placed in the sorted list. Since 10 it’s smaller than 29, it moves the higher element to the right and inserts the smaller one in the first position. Now the elements 10 and 29 represent the sorted list. The algorithm performs this exercise sequentially by extracting elements from the unsorted list on the right and comparing them with the elements in the sorted list on the left, to figure out in which position to insert them.
Insertion Sort is adaptive, which means it reduces its total number of steps if a partially sorted array is provided as input, making it more efficient. Like Selection Sort, Insertion Sort is not suitable for large data volumes where it looses against other sorting algorithms.
Bubble Sort
Bubble Sort is based on the idea of repeatedly comparing pairs of adjacent elements and then swapping their positions if they exist in the wrong order.
If a list of elements has to be sorted in ascending order, then Bubble Sort will start by comparing the first element of the list with the second one. If the first element is greater than the second one, it will swap both elements and move on to compare the second and third element, and so on.
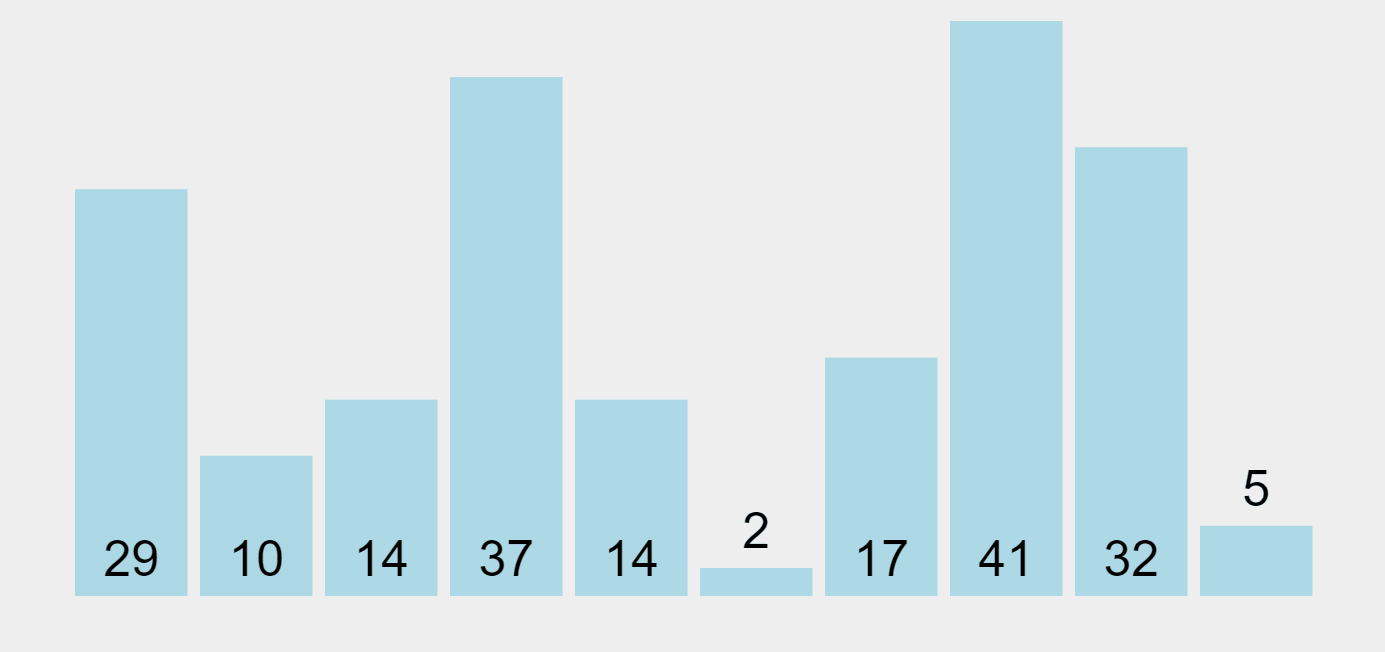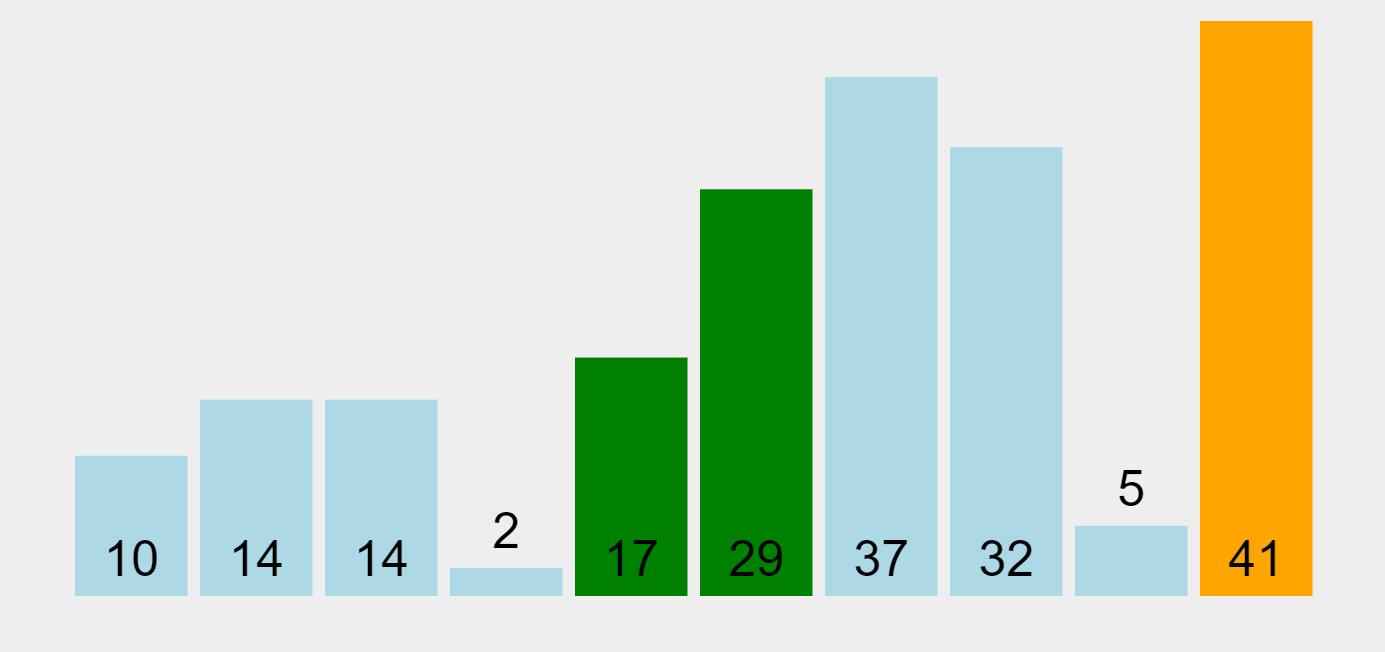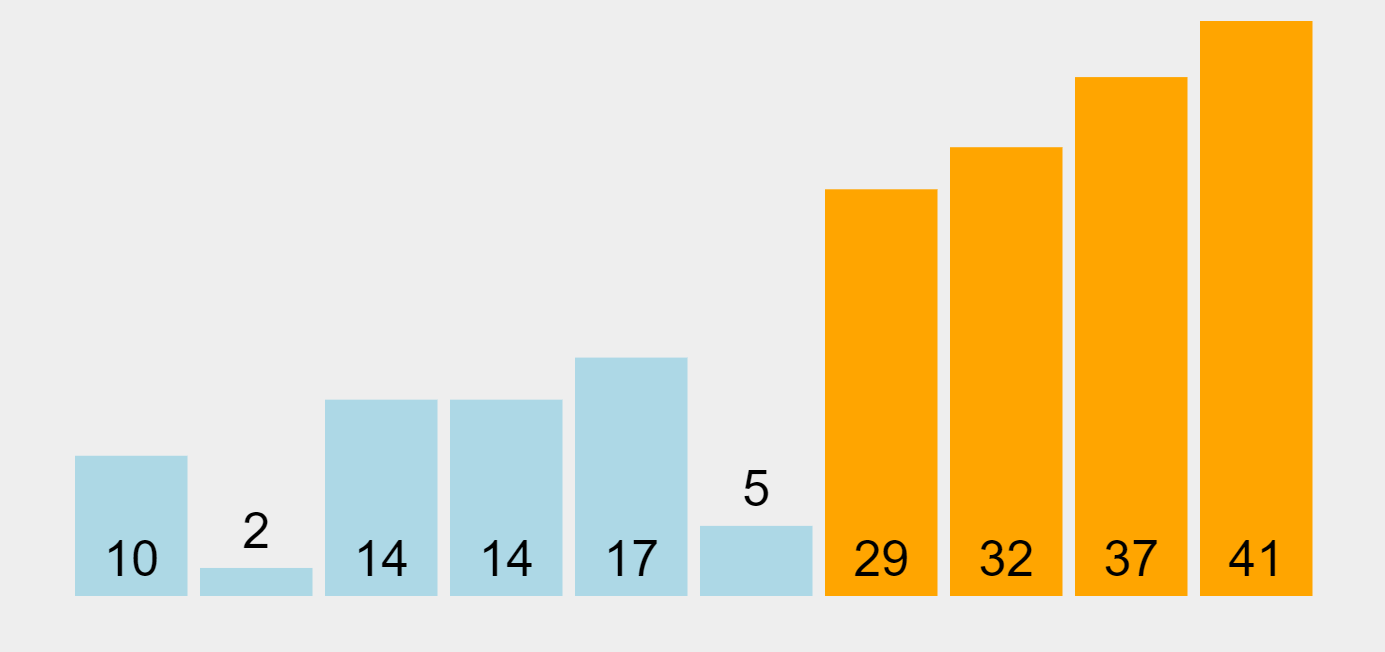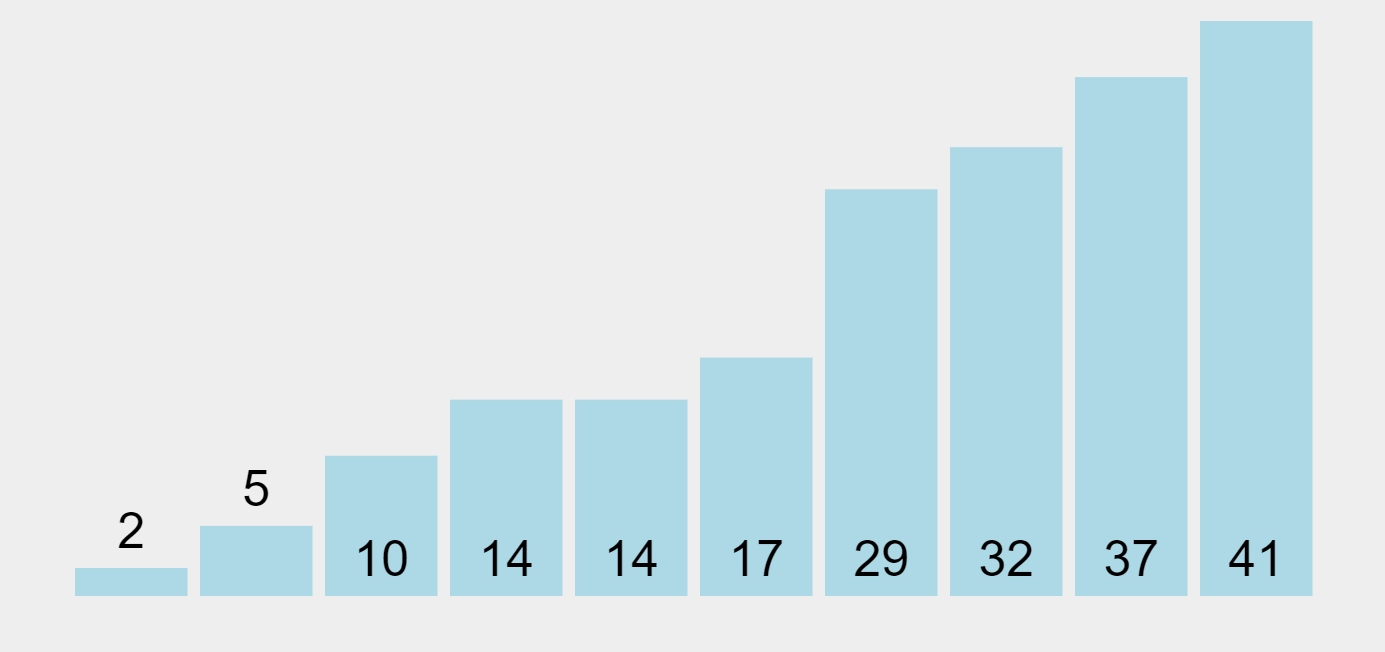
Bubble Sort Algorithm (ascending order)
In our example, the algorithm begins by comparing the first element (29) with the second one (10). Since 29 is bigger than 10, it swaps them and puts 29 as the second element in the list. Then, it performs the same operation with the second element (29) and the third one (14), and repeats this operation through all the list elements. As a result, the highest element in the list (41) will be placed at the end of the list (on the right) in the first pass. The algorithm will make multiple passes through all elements until they all get sorted, “bubbling up” each element to the location where it belongs.
Bubble Sort is often considered an inefficient sorting tool since it must exchange items before the final locations of the elements are known. However, if during a pass there are no exchanges, then we know that the list must be sorted. Bubble Sort can be modified to stop early if it finds that a list has become sorted, which provides it with the ability to recognize sorted lists.
Merge Sort
Merge Sort is a very efficient algorithm that divides the list of elements in equal halves, and then combines them in a sorted manner.
The algorithm starts by repeatedly breaking down a list into several sub-lists until each sub-list consists of a single element and can’t be split any longer (creates partitions of 1 element). The first elements of each sub-lists are compared between them and, if sorting in ascending order, the smaller element among both becomes a new element of a new merged sorted list. This procedure is repeated until all sub-lists are empty and one newly merged list covers all the elements of all sub-lists, resulting into one sorted list.
The secret here is that a list with a single element is already sorted, so once we break the original list into sub-lists which have only a single element, we have successfully broken down our problem into base problems. This method is know as “Divide-and-Conquer”, which is based on the idea of breaking a single big problem into smaller sub-problems, solve the smaller sub-problems and combine their solutions to find the solution for the original big problem.
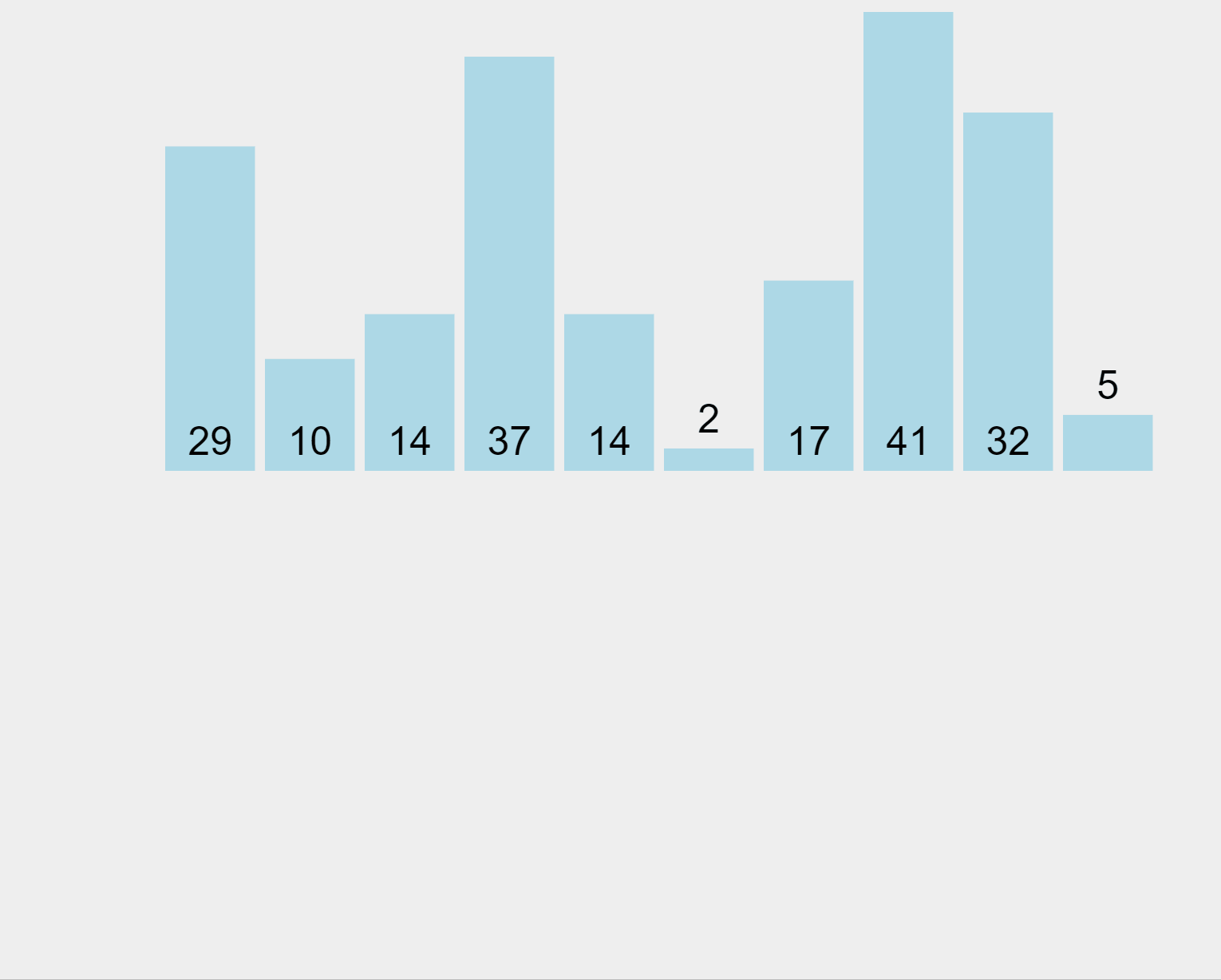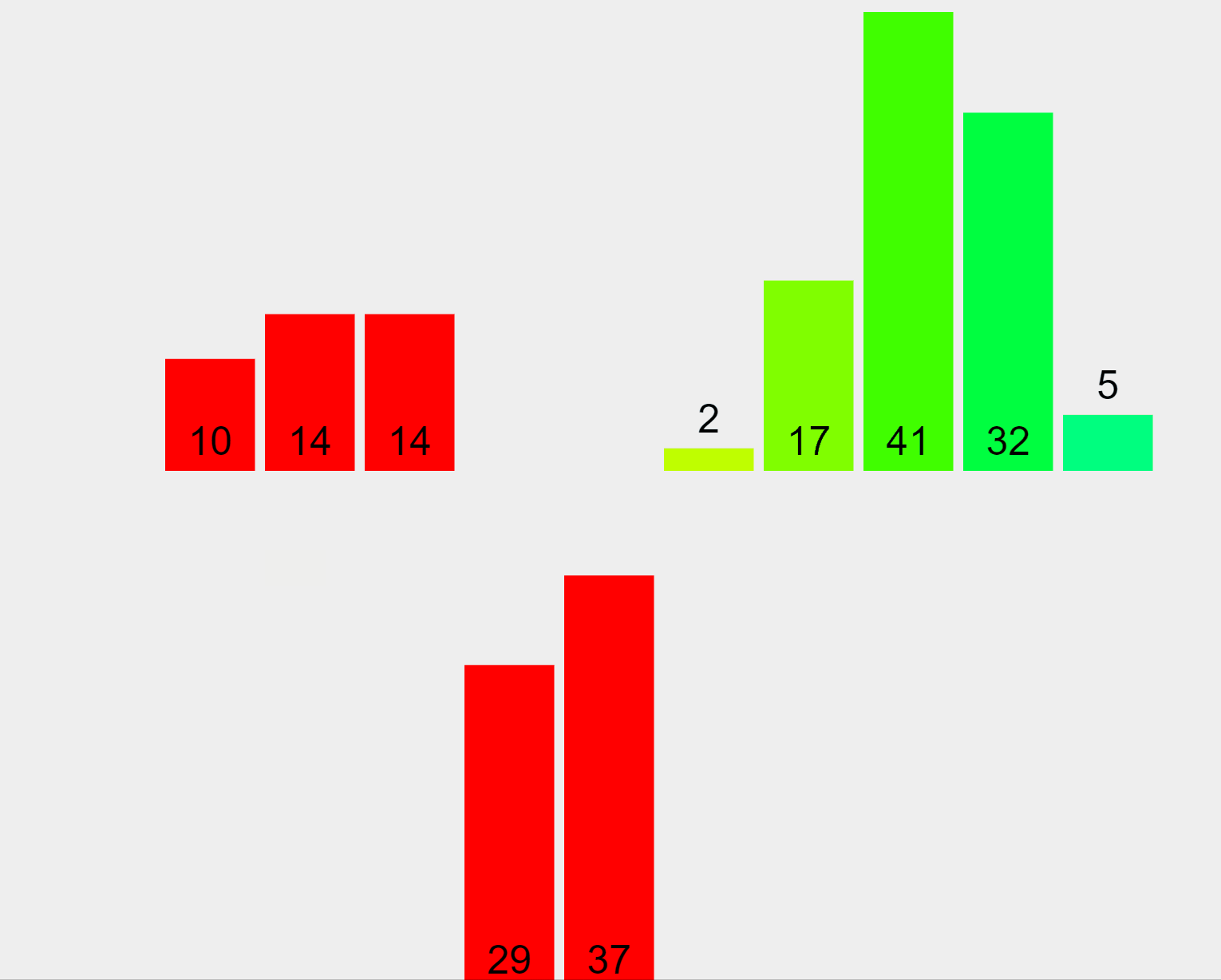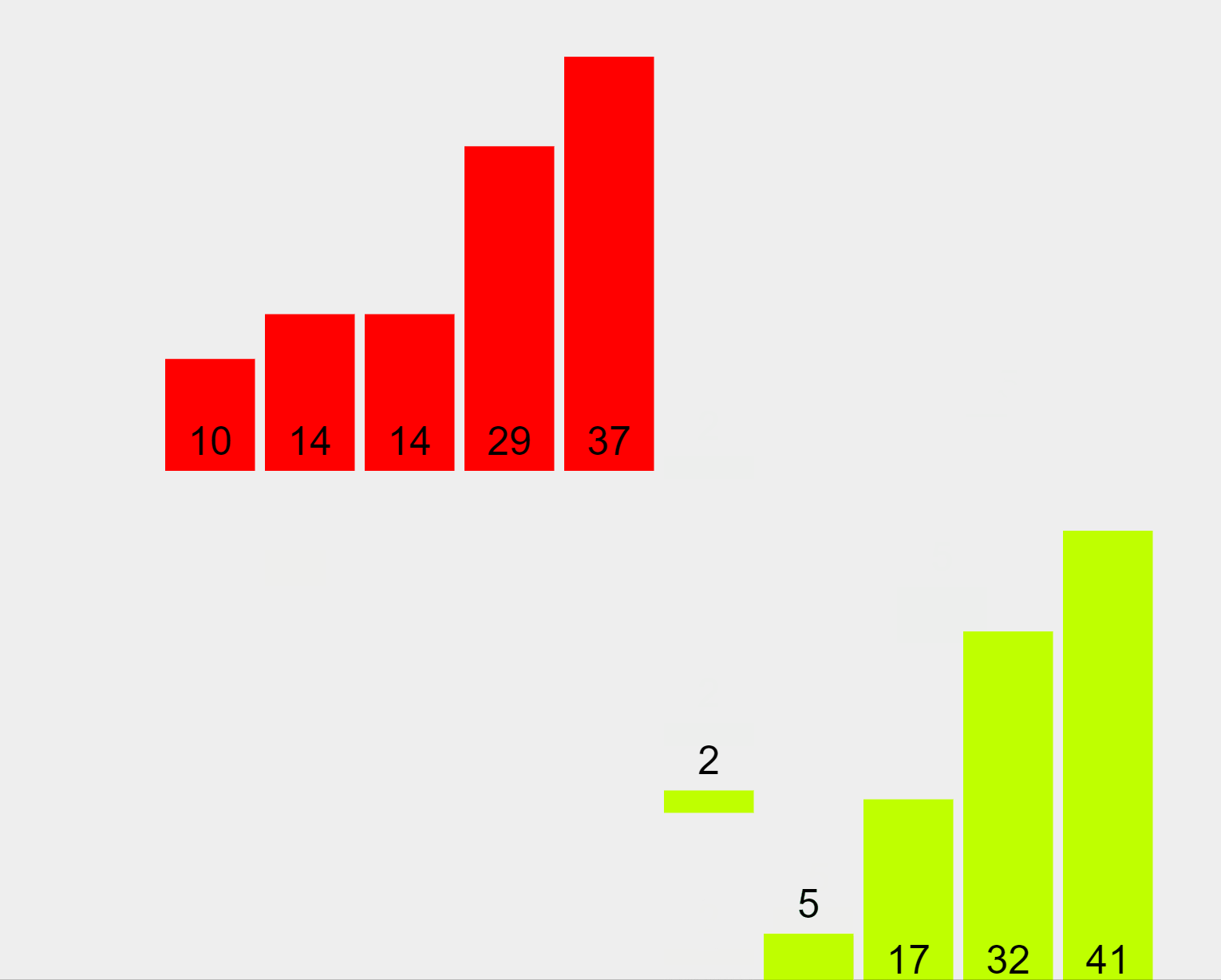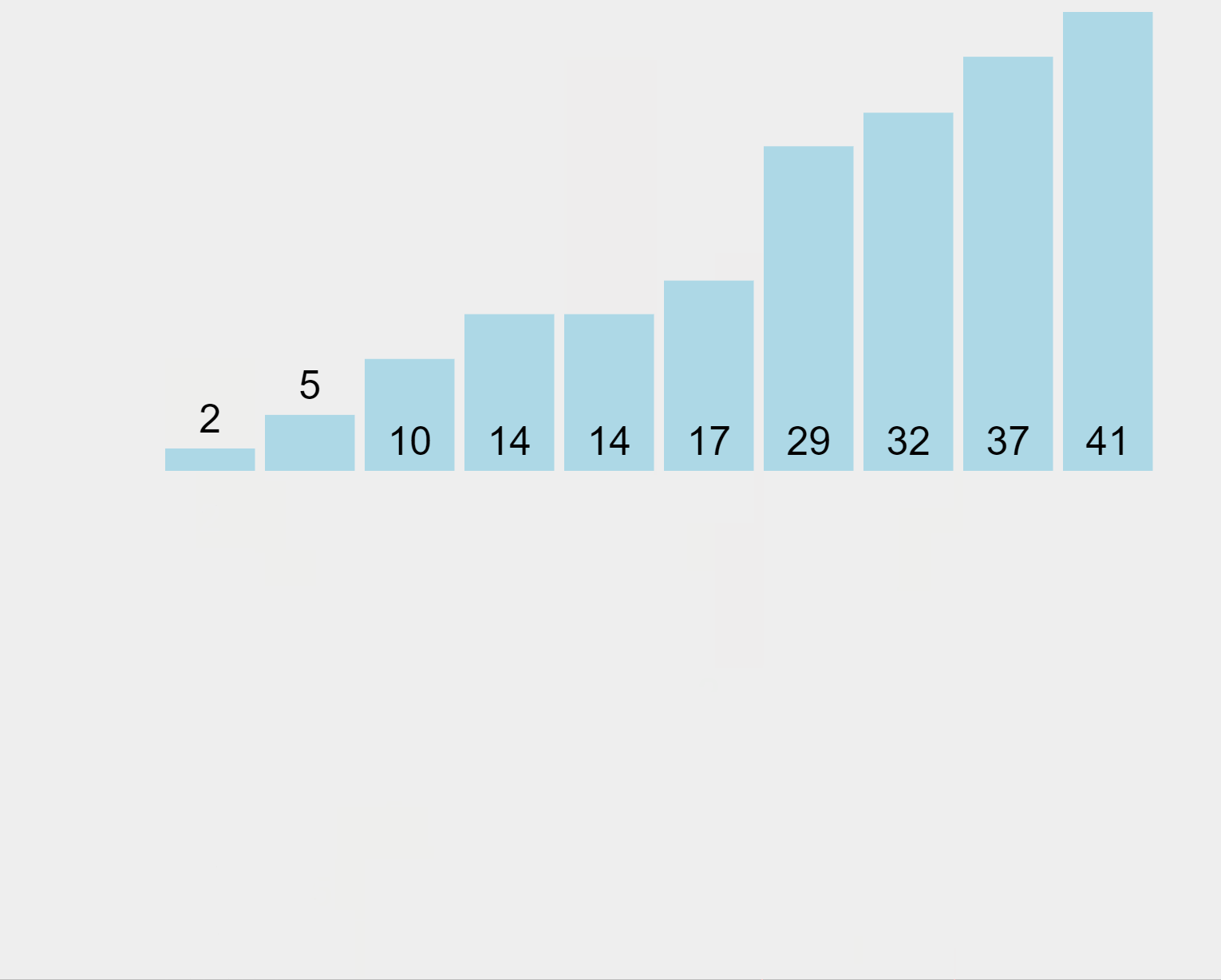
Merge Sort Algorithm (ascending order)
In our example, the algorithm begins by splitting the list of elements into partitions of 1. Then, it merges the first (29) and second (10) elements, sorts them (in this case in ascending order), and puts them back in the list. Afterwards, it merges the first (now it’s 10), second (which now is 29) and third (14) elements, sorts them, and puts them back in the list. It performs this process for all sub-lists, merging the sub-results until reaching a one-and-only sorted list.
Since Merge Sort breaks the input into chunks, each one of them can be sorted at the same time in parallel which produces extremely fast results.
Quick Sort
QuickSort is one of the most efficient sorting algorithms and is based on the splitting of a dataset into sub-groups, which are then recursevily divided into smaller groups to optimize the sorting process. This algorithm works by finding a “pivot element” in the dataset and using it as the basis for ordering.
Quick Sort also uses the “Divide-and-Conquer” method to divide and organize the elements around the pivot such that: left-side of pivot contains all the elements that are less than the pivot element, and right-side contains all elements greater than the pivot (this is called “partition”). This way, the pivot value starts by diving the whole elements into two parts, and works recursively by finding a pivot for each sub-division until all divisions contains only one element.
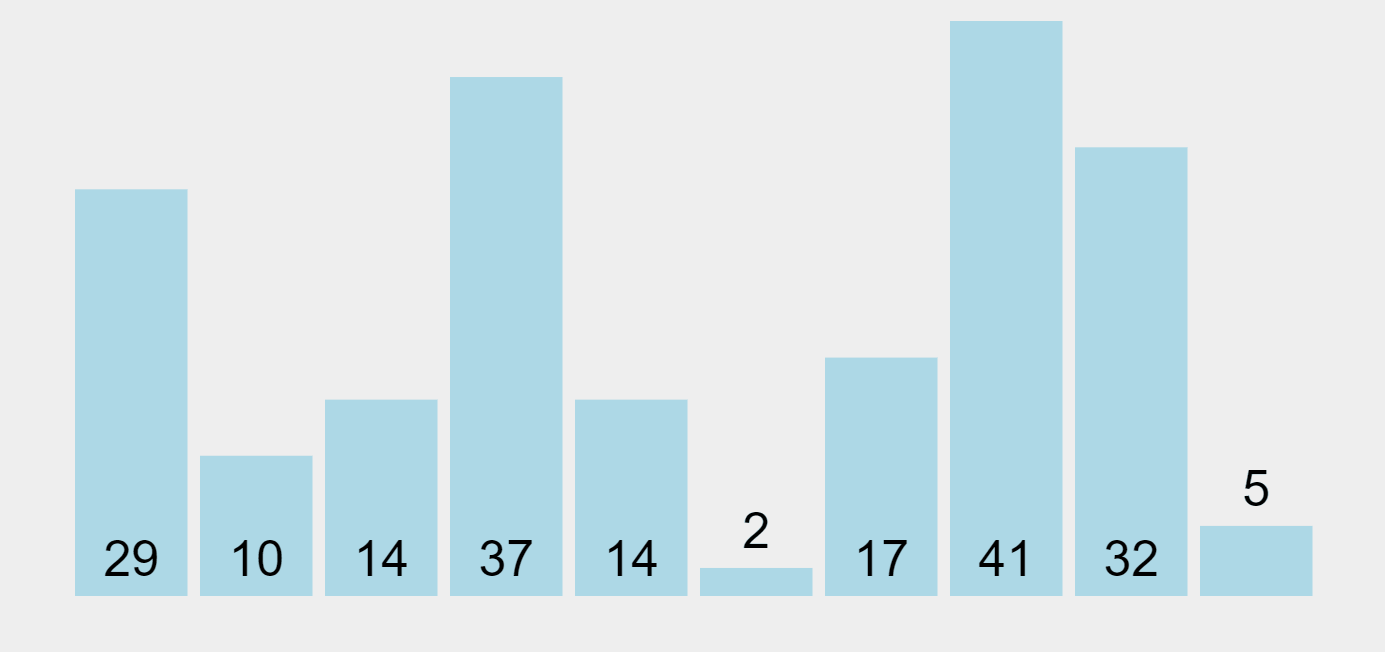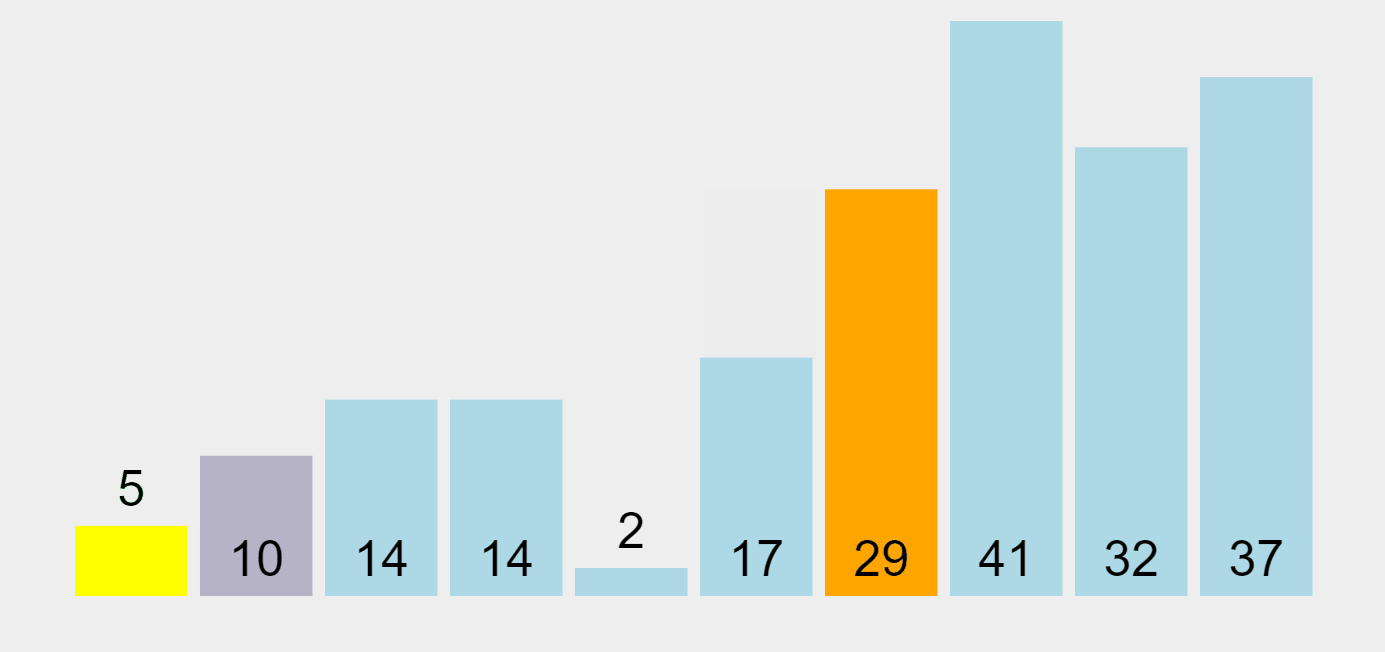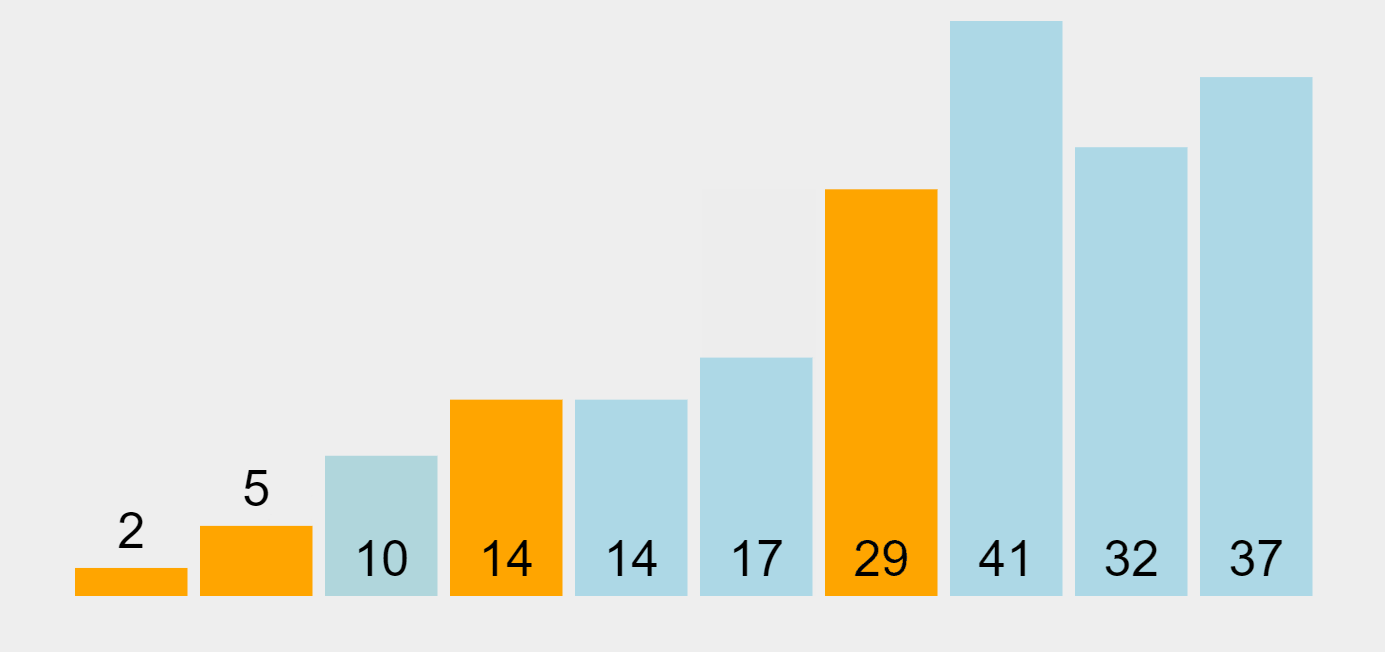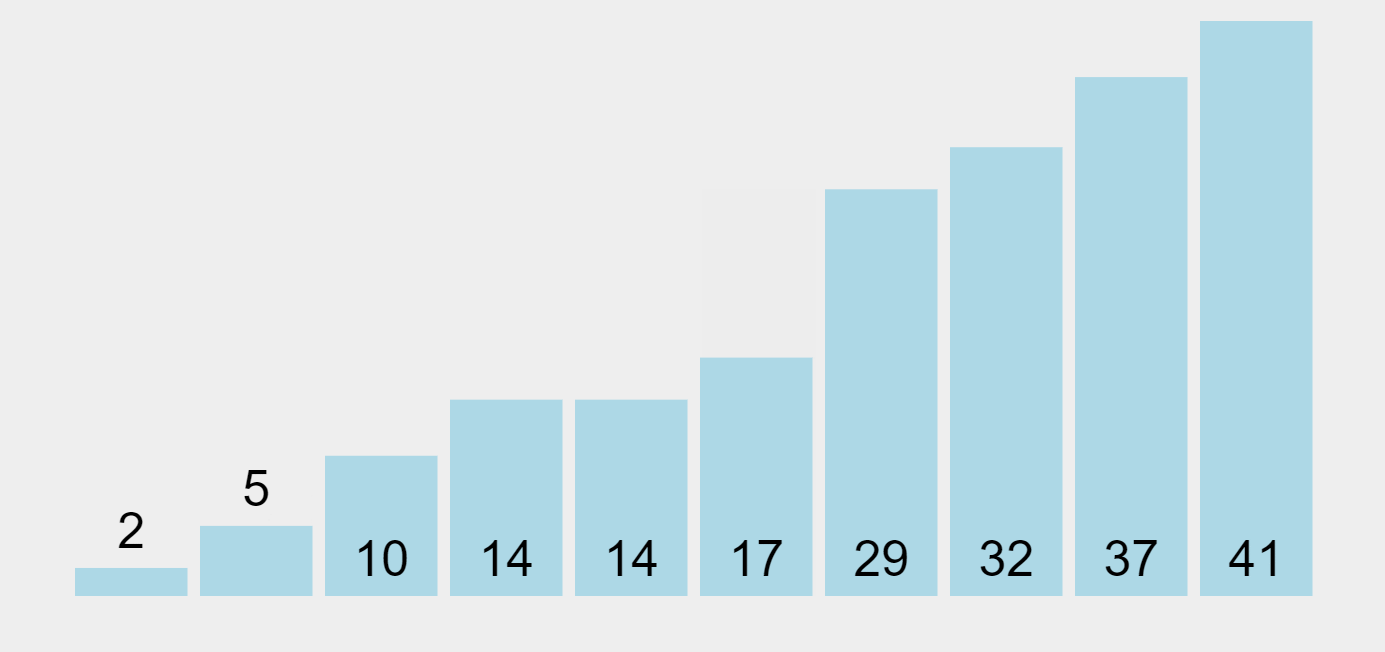
Quick Sort Algorithm
In our example above, the first element of the unsorted partition is chosen as the pivot element (highlighted in yellow). Elements that are smaller to it are marked in green and sorted to the left, and the ones that are higher are highlighted in purple and ordered to the right.
Let’s see the sequence. At the beginning, 29 (the first element on the left) is chosen as the pivot. When the pivot is placed in its proper position, all elements smaller than it are placed on the left (one sub-group), and the ones higher to it on the right (another sub-group). Then 5 (the first element of the left-hand side unsorted list) is picked as the new pivot element, and the whole process iterates until this side is sorted.
Once the left-hand side group is sorted, the algorithm moves on to the right-hand side unsorted group, and picks 41 (the first element on the left) as the pivot, and performs the same process on this side until the whole dataset is sorted from lowest to highest.
In Quick Sort, any element from the dataset can be chosen as the pivot: the first element, the last one or any other random element. So what is the best thing to do? As always, there isn’t one straight solution and it really depends on the problem you’re trying to solve. You can:
- Always pick the first element as pivot
- Always pick the last element as pivot
- Pick a random element as pivot
- Pick median as pivot
If the sub-divisions produced after partitioning are unbalanced (meaning that you get few elements on one side of the pivot but lots of elements on the other side), Quick Sort will take more time to finish. To avoid this, you can pick random pivot elements and diversify the risk of getting unbalanced partitions.
Which one to choose?
Naturally, computer scientists keep inventing additional sorting algorithms with their own advantages and disadvantages, so choose your sorting algorithms carefully. Pick the right sorting algorithm, and your program can run quickly. Pick the wrong sorting algorithm, and your program may seem unbearably slow to the user. As a general rule, Insertion Sort is best for small lists, Bubble Sort is best for lists that are already almost sorted, and Quick Sort is usually fastest for everyday use.
You get the picture: some algorithms are fast at managing relatively small numbers of items, but slow down rapidly if you force them to manage a large number of items. On the other hand, other algorithms are very fast and efficient in sorting items that are almost correctly sorted initially but slow if sorting items that you randomly scatter in the list.
But what if you could take the best of each one? Hybrid algorithms are the way to go.
A hybrid algorithm combines two or more other algorithms that solve the same problem, either choosing one, or switching between them over the processing course.
This is done to combine desired features of each, so that the overall performance is better than the one from the individual components. For example Tim Sort is a hybrid sorting algorithm derived from Merge Sort and Insertion Sort, designed to reach high performance on real-world data. The algorithm finds subsequences of the data that are already ordered (called “natural runs”), and uses them to sort the remainder more efficiently.
{kind=link}