
Announcements
- Achieving endpoint visibility to ward off the threat of a breach has never been more important than it is in the age of data proliferation and hybrid workplaces. Multiple endpoints and locations heighten that risk, making it essential for CISOs and IT security teams to overcome common challenges. Find out how organizations can reach true endpoint visibility to effectively secure their employees, customers, and supply chains. Register for the Successfully Securing Endpoints & Mitigating Threats summit to get free thought leadership from top IT Security and Threat Intelligence speakers, vendors, and evangelists in the form of live webinars, panel discussions, keynote presentations, and webcam videos.
- As IT Service Management drives Digital Transformation, 2022 is seeing investments in the discipline continue to grow. Thanks to innovations in AI and ML, ITSM has enabled businesses to survive the pandemic and transform organizations. As innovations continue to shape the face of ITSM, it’s time to take another look at the effect of automation on service management, DevOps, monitoring and metrics, and more. Join the Driving Innovation & Automation in IT Service Management summit to hear from experts as they uncover advances across the ITSM spectrum and share how your business can benefit.

From Knowledge Graphs to Transformations As A Service
Data integration is one of those areas that companies spend a lot of money on for remarkably little gain. This is a big issue because integration almost always occurs with extant data systems. A typical enterprise will sometimes have hundreds or even thousands of such systems that represent sunk costs most companies are reluctant to walk away from.
Services have evolved the same way. Most data systems are now accessible via a service, typically by passing a query to a data system and retrieving some form of JSON as a stream of information. While this has helped with integration to a certain extent, it has also pushed a significant amount of the business logic into applications. This approach tends to be brittle when dealing with large numbers of systems.
I’ve made the case before in these editorials about why I think knowledge graphs are important. Still, a reason that occurred to me recently makes their use very compelling: transformations as a service (TAAS). Yes, *blank*-as-a-service has become old-hat in this sector, and even data-as-a-service (which can be thought of as a service API on top of a database) has been around for a while. However, I think that transformation-as-a-service will prove to have some real value.
The idea behind TAAS is that most organizations generally have two kinds of data: transactional data and metadata. Transactional data, in general, binds together two or more keys – a vendor (vendorID) sells one or more products (productIDs) to a customer (customerID) for a certain amount per item as part of the transaction (transactionID). Now, there’s a lot of metadata associated with those keys – the vendor, their product lines, prices, discounts, descriptions, locations, any specialized relationships that the vendor has with the company in question, and so forth. The metadata are fairly critical to the process of both buying and selling not just during this transaction but hopefully across many others. Similar relationships exist in supply chain management, healthcare and health insurance, manufacturing, education, etc.
Knowledge graphs are generally not all that great at handling transactional data (at least for now, but that’s changing). More to the point, most organizations already have systems for managing that transactional data. On the other hand, with transactional data, you ideally want to provide the absolute minimum necessary amount of metadata because that impacts how many transactions you can manage a second. This means that if your transactional systems focused solely on recording the identity keys for the resources in question, they would be considerably more efficient, and applications built around those transactions would require considerably less complexity.
Knowledge graphs might not work well with transactional systems, but they are fantastic when managing metadata. They are so good because you can retrieve connected, dynamic information from a knowledge graph as a structured document (in JSON or XML) as well as retrieve tabular data. What’s more, if you associate a particular resource (such as a customer, a vendor, a product, a point of purchase, or other entity), then you can use the knowledge graph to manage the keys that different systems use to identify the same resources across different data systems in a way that’s superior to the way that most master data management systems work.
What’s more, (and here’s where TAAS comes in) if you pass a document containing transactional data with just the associated keys, the knowledge graph can identify each key and retrieve an arbitrarily deep structured document that can get bound to those keys. So if I buy a box of Fruity Whirlos from the Kello Gmills cereal company, the transactional database would tell me the SKU (1510CGK). Still, the Transformation As A Service Knowledge graph will then be able to supply the fact that it is Fruity Whirlos, 48 oz., with the Blue, Green, and Purple Flamingo on the cereal box, produced by Kello Gmills, and sold to Kurt Cagle. He probably shouldn’t be eating so much sugary cereal.
How does this work? A script takes the transactional document as input, identifies the keys, then replaces the keys with objects containing all of the associated metadata pulled from the knowledge graph with the appropriate fields for the product type (e.g., cereals vs. coffee). This then gets passed back to the requester, who can work with far richer content than before.
The advantage of this approach is that any number of different data systems could use the knowledge graph, which acts as a repository for ALL of the metadata that the whole enterprise uses. The knowledge graph may also extract information from the document that can be used for analytics. The same TAAS system with the knowledge graph could also be employed with analytics engines, as the knowledge graph can appear from the outside as a JSON, XML, or relational data store. The key point, however, is that because multiple systems can use the same object data contained in the knowledge graph, you do not have to store data redundantly. Moreover, such knowledge graphs are readily federated, meaning such systems can adapt as scale and volume increase in ways that normal relational databases find challenging to manage.
This just hints at what such a system can do, however. Transformations are key parts of process pipelines. Knowledge graphs can act as unified integration platforms by treating such pipelines as services (especially when such pipelines can operate in both push and pull modes).
In media res,
Kurt Cagle
Community Editor,
Data Science Central
Data Science Central Editorial Calendar: August 2022
Every month, I’ll be updating this section with a lot of topics that I’m especially looking for in the coming month. These are more likely to be featured in our spotlight area. If you are interested in tackling one or more of these topics, we have the budget for dedicated articles. Please contact Kurt Cagle for details.
- Climate Change and Sustainability
- An AI Snowstorm?
- Personal Knowledge Graphs
- Gato and GPT-3
- Labeled Property Graphs
- Future of Work
- Data Meshes
- ML Transformers
- Energy AI
- RTO vs WFH
If you are interested in posting something else, that’s fine too, but these are areas that we believe are hot right now.
DSC Featured Articles
- 5 Growth Pillars of Smart Learning and Education
Nikita Godse on 19 Jul 2022 - Google Ads Headlines: How To Write Headlines That Get More Clicks
Edward Nick on 19 Jul 2022 - Healthcare Industry: The Impact of Business Intelligence
Ryan Williamson on 19 Jul 2022 - Factors to Consider while Developing Mobile Apps
James Wilson on 19 Jul 2022 - How Annotations Can Transform AI Training Data
Roger Brown on 19 Jul 2022 - Understanding the Value of Bayesian Networks
ajitjaokar on 19 Jul 2022 - How Blockchain Is Changing the Accounting Profession
KathieAdams on 19 Jul 2022 - The Impact of AI on Sports Betting and Its Software
Ryan Williamson on 19 Jul 2022 - What Do NBA Champions and CDOs have in Common? Success Requires Being 2-way Players
Bill Schmarzo on 18 Jul 2022 - Top 7 Online Form Builders for Higher Conversion Rates
Edward Nick on 18 Jul 2022 - DSC Weekly 12 July 2022: The Emergence of the Modern Studio Model
Kurt Cagle on 14 Jul 2022 - The Business Impact of Robotic Process Automation
Scott Thompson on 14 Jul 2022 - Why We Need to Move From Data-First to a Knowledge-First World
Juan Sequeda on 12 Jul 2022 - Real-Time Apps: Why Node.js is the Ideal Choice
Ryan Williamson on 12 Jul 2022 - Web Analytics Dashboards Carry a World of Data for Various Purposes
Karen Anthony on 12 Jul 2022 - Top Picks for Blockchain Certifications
KathieAdams on 12 Jul 2022
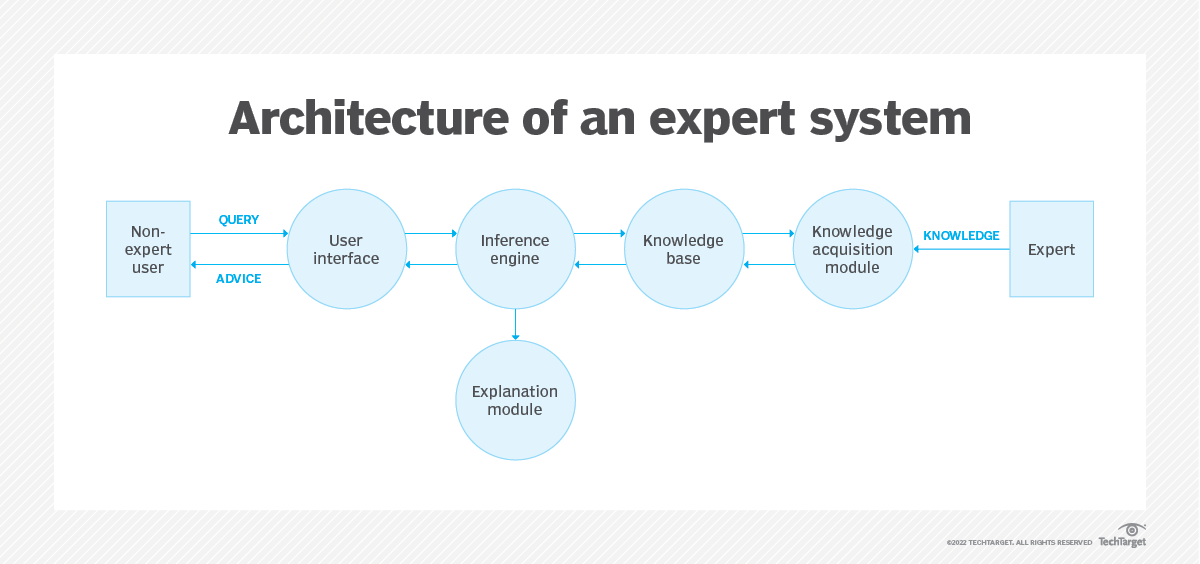
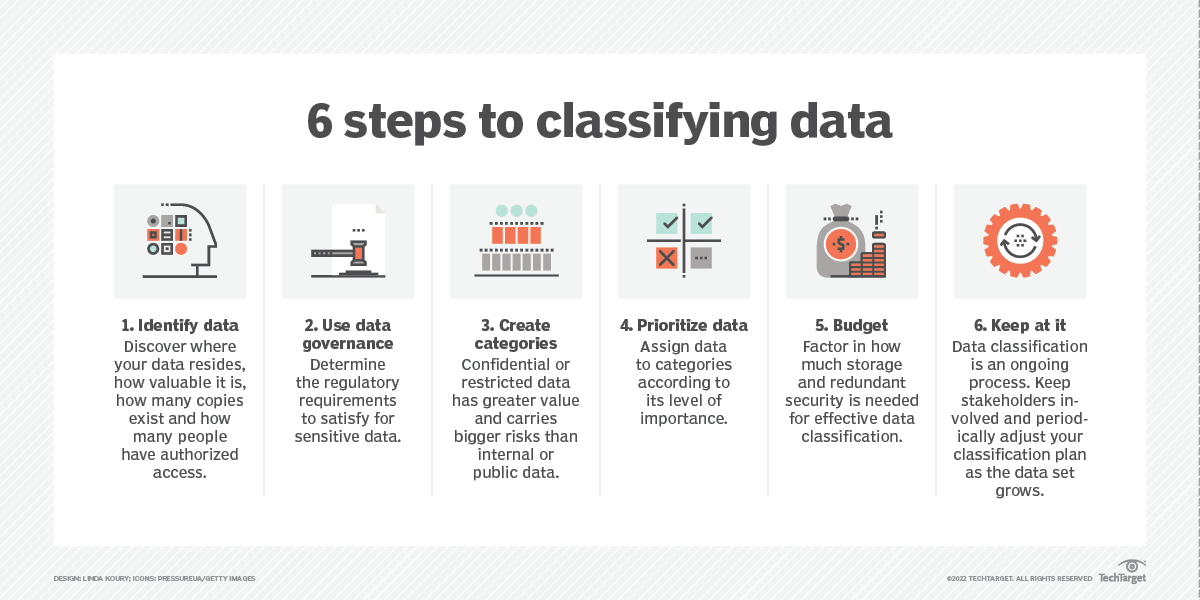
Picture of the Week
{kind=link}
{kind=link}