

I attended an in-person customer event sponsored by Dataiku last week. Very fun. Man, do I miss the provocative and enlightening discussions that occur in these face-to-face customer engagements.
The icebreaker for fueling the dinner discussions was the following statement:
“In the marketplace, dynamics in the job marketplace will evolve, and data-savvy subject matter experts will be paid higher than data scientists.”
Totally agree. This is what I tell my students as part of my “Big Data MBA” class. I believe that the folks that will benefit the most from data and advanced analytics will be those who master the application of data and analytics to derive and drive new sources of customer, product, service, and operational value. And I believe that the biggest inhibitor to data and analytics value creation isn’t the lack of data scientists, but the lack of skilled folks who understand how to provide that clear line of sight from value to data.
I made my case for why we need more business users skilled in the use of data and analytics to drive value in “Why Data Management is Today’s Most Important Business Discipline”. My rationale was as follows:
- Artificial Intelligence (AI) is the most powerful business value enabler of our generation (with AI’s ability to continuously learn and adapt to create new sources of customer, product, service, and operational value).
- The ability for AI to drive effective and responsible decisions is totally dependent upon high-quality, accurate, complete, unbiased data sets.
- Data management is focused on gathering and curating high-quality, accurate, complete, unbiased data sets that fuel the AI’s learning effectiveness in improving the organization’s decision-making and business outcomes effectiveness.
- Thusly, Data Management is the most important Business Discipline of the 21st century
IF A (AI most powerful economic force) = B (AI requires high-quality data), AND B (AI requires high-quality data) = C (data management manufactures high-quality data), THEN A (AI most powerful economic force) = C (data management) yields D (Data Management most important business discipline), right?
In this blog, I want to discuss some modern data management developments and concepts, and what’s being done to mitigate the role of the data scientist in helping organizations exploit data and AI / ML to drive business innovation.
How AutoML Could Reduce Data Scientist Dependencies
There is lots of excitement about the potential of Automated Machine Learning (AutoML) to accelerate and automate the data scientists’ AI/ML model discovery, testing, and model development processes.
Automated Machine Learning (AutoML) accelerates the data scientist ML algorithm selection process by applying AI / ML to automate the exploration and testing of a wide range of ML algorithms against a given data set to determine which ML algorithms are the best fit (Figure 1).
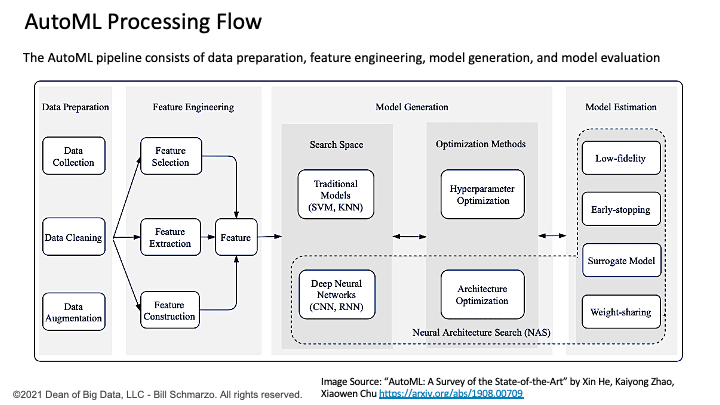
Figure 1: AutoML Processing Flow
Yes, it is conceivable that the heavy reliance on the data scientist in the data science value creation process will be alleviated by AutoML to automate the discovery, exploration, testing, and validation of the AI / ML models that power the organization’s decision-making and business outcomes effectiveness.
However, if 70% to 80% of the work in achieving data-driven business innovation is in data ingestion, data preparation, and data management, then we are focusing AI/ML on the wrong problem. Instead of focusing AI/ML on AutoML to accelerate ML model discovery, validation, and development, maybe we should focus AI/ML on automating data management (what I will call AutoDM) to accelerate and automate the data management and data engineering work?
Andrew Ng, the Godfather of AI, has talked about the importance of shifting AI practitioners’ focus from tweaking the AI / ML algorithms and frameworks to improving the quality and completeness of the data that fuels the learning effectiveness of those AI / ML algorithms and frameworks. That is, that while tweaking the AI/ML algorithms will help, much bigger improvements in business and operational outcomes can be achieved by improvements in the quality and completeness of in the data that feed the AI/ML algorithms.
Consequently, in an era where AI / ML has the potential to re-invent business processes and transform business models, we must consider data management the most important business discipline in the 21st century.
Data Management Basics
Conceptually, data management seems very straightforward. Gather a bunch of data, run it through some data cleansing and alignment processes, store the data in some data repository, and then open the doors and let the data consumers at the data (Figure 2)!
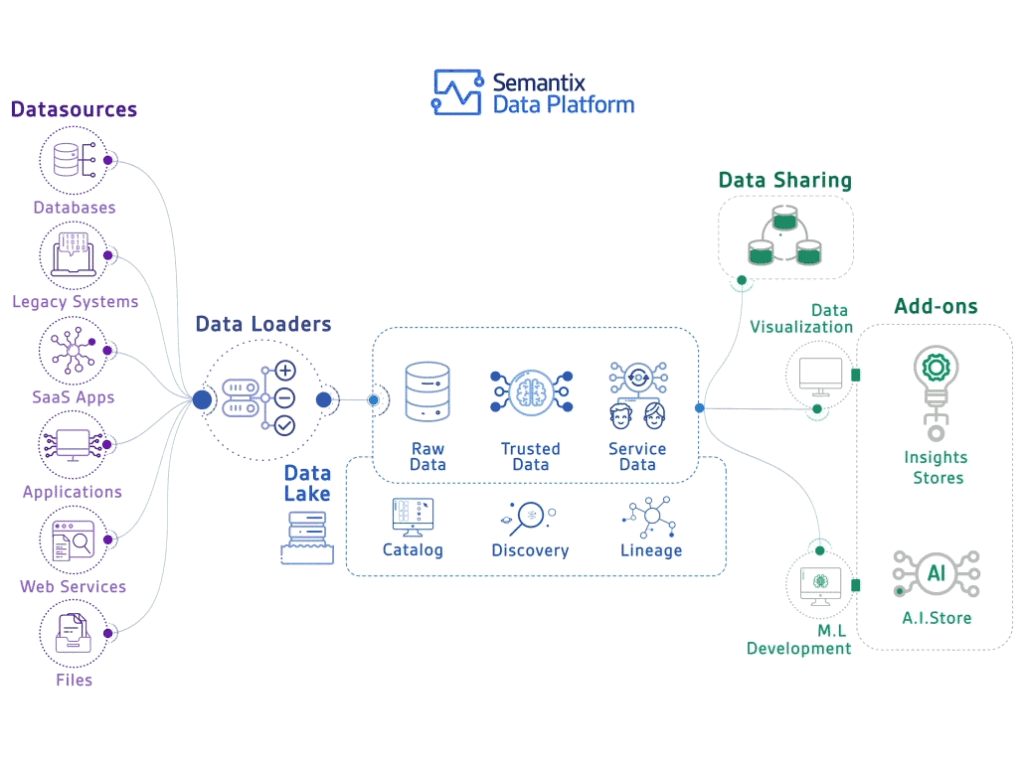
Figure 2: Data Management Processing Flow courtesy of Semantix Brasil
I wish it was that easy (of course, then I’d be unemployed).
The realities of data management are very different. For example, there is a concept of data as Lego blocks that can be clicked together to build any structure (pirate ship, star cruiser, castle). Great metaphor, if only data had well-defined, carefully architected, consistently engineered Lego studs. Unfortunately, we are not connecting nicely engineered Lego blocks, but instead are cobbling together radically different Lincoln Logs, Tinker Toys, K’Nex, Magna-tiles, straw construction tubes, bristle blocks, and erector sets (Figure 2).
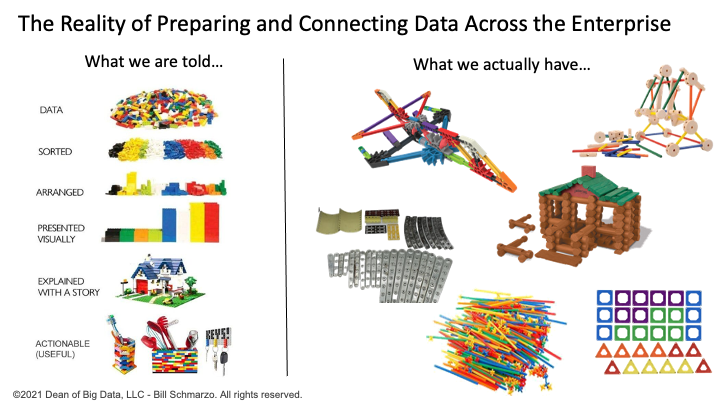
Figure 3: Data Management Reality
The extensive amount of work that needs to be done in the areas of data assembly, data accessibility, data cataloging, data quality, data governance, metadata tagging, cataloging, data enrichment, data transformation, etc. requires significant amounts of human-intensive work before organizations can leverage the transformational power of AI / ML.
So, what role can AI / ML play in helping to create an automated data management platform to help to unleash the business potential of data management?
Automated Data Management (AutoDM) to the Rescue
We need to extend the AutoML conceptual process in Figure 1 to fully understand where and how to apply AI / ML to automate and optimize the organization’s data management tasks. This means expanding the AutoML architecture to include (Figure 4):
- Determining Data Consumer Intent. That includes discovering what each Data Consumer is trying to accomplish (their intentions), capturing the Decisions that they need to make in supporting their intentions, identifying the KPIs and metrics against which decision effectiveness will be measured, and quantifying the costs associated with False Positives and False Negatives.
- Measuring and Optimizing Business Outcomes Effectiveness. That includes measuring how actual business outcomes compare to what was predicted (and continuously learning from the differences), creating an instrumentation strategy for measuring and learning from AI model False Positives and False Negatives, and continuously learning, adapting, and refining the AI / ML models’ effectiveness (think Stochastic Gradient Descent and Backpropagation).
- Capture, Reuse, and Refine Data Usage Learnings. That includes a contextual knowledge center for capturing and codifying the individualized data consumer usage trends, patterns, and relationships, centralizing and promoting the reuse of the organization’s composable, reusable, continuously refining data and analytic assets (the heart of the Schmarzo Economic Digital Asset Valuation Theorem), and delivering data and analytic usage recommendations to create a hyper-personalize data consumer experience.
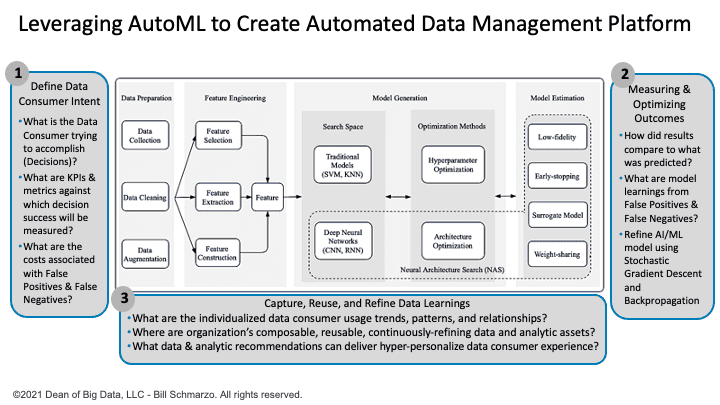
Figure 4: Creating an Intelligent Automated Data Management (AutoDM) Platform
There are companies that are trying to automate some of the key data management processes. For example, Snorkel AI seeks to accelerate feature discovery and data engineering by automate the labeling of data. Snorkel leverages AI to programmatically label large amounts of training data using labeling functions such as rules, heuristics, and custom operators. Snorkel automatically learns labeling functions’ effectiveness, de-noises and integrates them, and stores versioned labeling function packages and training data for reuse (Figure 5).
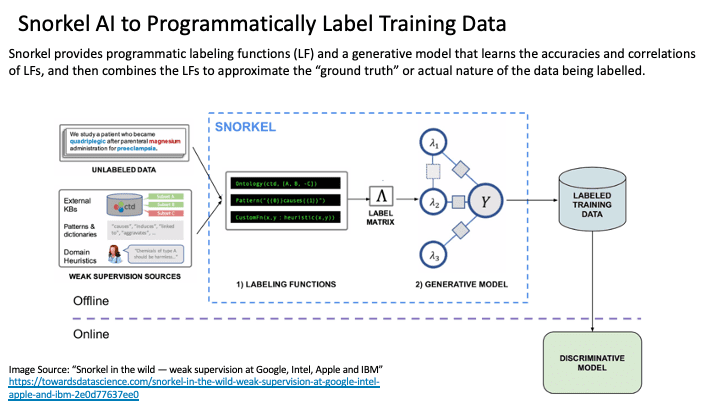
Figure 5: Snorkel AI to Automate Labelling AI / ML Model Training Data
Summary: Creating the Next Generation Data Scientist
“In the marketplace, dynamics in the job marketplace will evolve, and data-savvy subject matter experts will be paid higher than data scientists.”
A good next generation data scientist will still need critical data science skills including:
- A deep understanding how each of the many AI/ ML algorithms (clustering, regression, classification, neural networks, reinforcement learning) can do and against which types of problems to best apply which AI / ML algorithms (Figure 6).
- Assembling or orchestrating a value chain of AI / ML models to optimize a business or operational outcome (e.g., unsupervised machine learning for data labeling, deep learning for unstructured object classification, supervised machine learning to identify the most influential variables, reinforcement learning to continuously learn and adapt).
- Building AI/ML feedback loop that instruments, measures, and continuously learns from AI / ML model’s actual versus predictive results, as well as learning from the AI / ML model’s False Positives and False Negatives. This includes envisioning what additional data sources and process instrumentation might be necessary to capture, track, and learn from the AI / ML model’s False Positives and False Negatives.
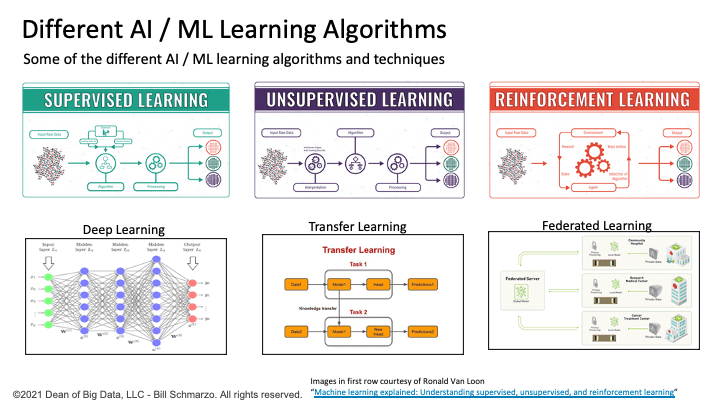
Figure 6: Different Types of AI / ML Learning Algorithms
However, if AutoML and AutoDM are going to replace many of today’s data scientists’ tasks, what new skills will the next generation data scientist need to master? How about these as a starting point:
- Business Management skills (Big Data MBA) to identify, validate, value, and prioritize the business and operational use cases that supports an organization’s key initiatives. This includes identifying and validating the desired outcomes and capturing the KPIs and metrics against which outcomes effectiveness success will be measured.
- Design Thinking skills to uncover and validate the heuristics and rules of thumbs that business and operational subject matter experts use today to make decisions. These heuristics and rules of thumbs might provide insights into the feature engineering process to identifying those features might be better predictors of performance.
- Group Facilitation skills (again using Design Thinking techniques) that fuels stakeholder brainstorming and ideation to identify the KPIs and metrics against which decision success / effectiveness will be measured (and against which AI / ML models will seek to optimize).
- Financial Modeling skills to facilitate business collaboration to define and quantify the costs of False Positives and False Negatives in order to determine when an AI / ML model’s accuracy, recall, and precision levels are “good enough”.
It won’t be sufficient for the next generation data scientist just to master building data pipelines and training AI / ML models. The next generation data scientists will also be prepared to lead organizations in applying data and analytics to deliver new sources of customer, product, service, and operational value.
Maybe I need to add Value Engineering to that list of next generation data scientist training…
{kind=link}