

Real-world production ML systems consist of two main components: data and code. Data is clearly the leader, and rapidly taking center stage. Data defines the quality of almost any ML-based product, more so than code or any other aspect.
In Feature Store as a Foundation for Machine Learning, we have discussed how feature stores are an integral part of the machine learning workflow. They improve the ROI of data engineering, reduce cost per model, and accelerate model-to-market by simplifying feature definition and extraction.
While feature stores are important, they handle just one type of data that is specific to the ML workflow. There are many more types of ML-specific data, and as an ML Engineer, you should have a convenient way to discover, validate, and monitor all of them.
In the same way that a feature store acts as a warehouse of features to benefit machine learning, data catalogs can help you access all types of data entities (including feature stores) that data and ML engineers need in order to tackle both code and data aspects of ML models.
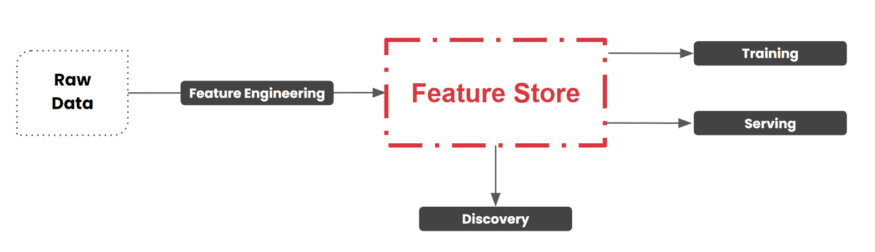
This article provides an overview of a type of data catalog that could combine the efforts of DE and DS teams, facilitate data-centric MLOps, improve TTM of ML models and remove the barriers to scaling ML/AI efforts of organizations – and explains why all of this matters for ML Engineers.
Why ML Engineers Need a Data Catalog Designed for Machine Learning
Even without taking into account the ML Engineer’s workflow, it can be challenging to make the most of data, primarily due to the following trends:
- The volume and complexity of data formats are skyrocketing
- Data pipelines are becoming too complex to be handled effectively with existing tools
- Modern requirements for data discovery are evolving faster than solutions to address them
The ML model lifecycle also poses additional challenges:
- ML pipelines are increasingly complex
- Siloed discovery of ML and data entities prevents scaling of ML operations
- Tools for the discovery and observation of ML entities along with data have not yet evolved
Data catalogs and observability tools that exist today have not yet been integrated with ML entities — at least, not on the architectural level. While factoring in machine learning has been considered, it is evident that:
- Data discovery tools do not include ML-related data entities
- ML entities are absent from lineage and observability tools
- When data in the ML pipelines goes wrong, stakeholders are kept in the dark about it
- Data and ML engineers are unaware of what is happening in the other’s part of the pipeline, and that hinders their collaboration and synergy
- The collaboration gap between DE and ML teams causes black box issues that are hard to detect, which often leads to loss of profits and damaged reputations
Since the advent of machine learning, ML-related entities (such as ML pipelines, ML models, features stores, etc.) have become integral to the data landscape. Despite this, and the role of data as a key component that defines the quality of ML products, they are still absent in existing data discovery and observability solutions.
Until recently, data catalogs and observability platforms were not designed to include ML entities as first citizens. The overall picture looked like this:
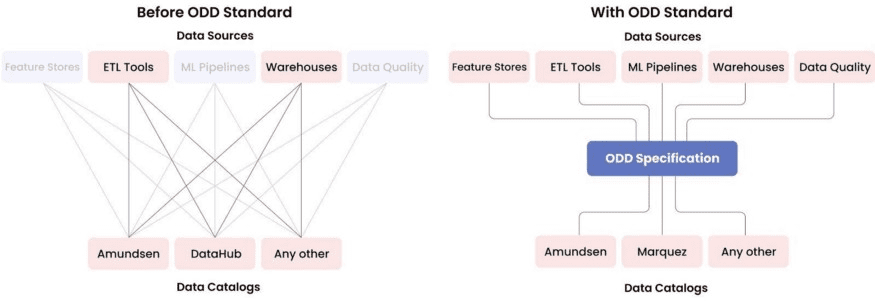
In our latest article entitled The Missing Piece of Data Discovery and Observability Platforms: Open Standard for Metadata, we take a closer look at the state of data catalogs and observability platforms. We also explain why they are struggling to keep pace with the rapidly evolving demands of professionals in the data and ML spheres.
Consequences of Siloed Data and ML Discovery
At the outset of a machine learning project, the first step immediately after understanding the business use case is data discovery — the process of searching, understanding, and evaluating data to satisfy your goals. Since the quality of products powered by machine learning depends so closely on the quality of data, it is important to find data that can be trusted to work with your model.
Data catalogs are a tool category designed to help with the discovery step. But the problem is that none of the existing data catalogs were designed with the needs of ML Engineers and the ML model lifecycle in mind. While they offer data search and evaluation capabilities, you cannot use them to discover all of the ML-related entities from platforms where you discover other types of data.
ML-specific dataflow includes a lot of entities that are part of the ML lifecycle: ML pipelines, model experiments, model metrics, model artifacts, ML production services, etc.
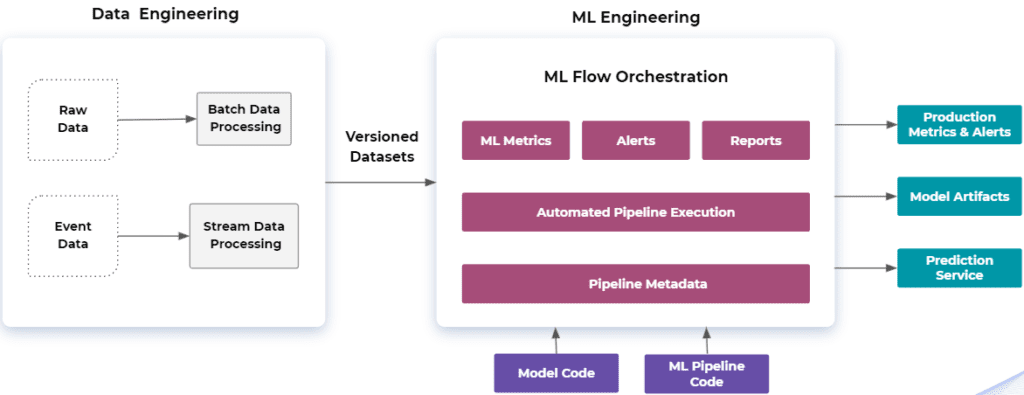
The unnatural gap between data discovery and other steps of the ML workflow creates inefficiencies in managing ML-related data operations.
In order to build an ML model that can generate maximum business value, it is crucial to have a whole picture of where data originated, how it has evolved, and its specific characteristics.
Machine learning entities that cannot be discovered can disrupt and slow down the entire process of working with data in the context of ML. It is impossible to manage what cannot be discovered and evaluated. As a result, data-driven organizations find it increasingly challenging to scale ML to its full potential. Disregarding ML in the data discovery workflow also strips companies of crucial opportunities to scale their ML and AI operations.
Consequences of Siloed Efforts of DE and ML Teams
The absence of ML entities in data discovery tools also means that the data and ML engineering portions of the data pipeline are siloed, keeping each team in the dark about what’s happening on the other side. This lack of observability can potentially cause unpredictable and hard-to-detect black box issues.
A classic example of a black box failure caused by lack of cross-department collaboration is undetected data tardiness. Imagine that you have a data and ML pipeline for a website’s recommendation model that two departments/teams are responsible for: Data Engineering and Data Science. The DE team uses Airflow to ETL and publishes data to a feature store, and the DS team supports a Kubeflow training pipeline that uses data from the feature store.
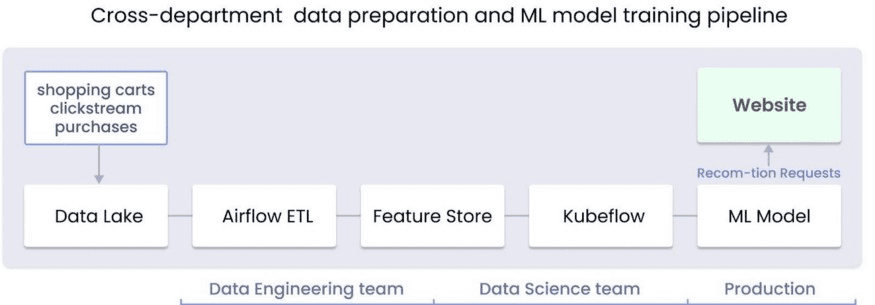
Without proper observability in place, it can be almost impossible to notice occasional changes in the algorithm.
For example, if the DE team deploys a new version of the Airflow ETL pipeline, scheduled to run daily at 12:00 am, while the ML training pipeline runs daily at 1:00 am, it would be difficult to notice that the Airflow pipeline execution time increased from 1 to 1.5 hours, and now terminates after the ML pipeline begins, lagging behind.
The model would end up constantly running on obsolete data from the previous day, without taking into account new data gathered throughout the day.
What ML-Related Data Can Be Gathered and Discovered?
Data has become extremely complicated, and modern tools for keeping track of ML-related entities in the same ways that data catalogs keep track of other types of data have not yet evolved. Such a catalog could help to plan and run ML training, experiments and tests, improve model-to-production time, and make for cleaner model development.
These catalogs can involve complex entities and relationships, which is why it’s important to be in control, and to be able to track those entities automatically.
As an ML engineer, you can use existing data catalogs to discover proper training data. But what about other artifacts that should be integral to your work process?
A simplified ML model lifecycle looks like this:
- Understanding the business case
- Data discovery (finding the right data for model training)
- Running experiments
- Training the model
- Finding the right data for model inferencing
- Model inferencing (running the ML model on new data to get predictions)
ML experiments. When working on an ML model, you have to run a lot of experiments — procedures to test your hypothesis (questions about your model, like which model performs better). You run experiments to see how different parts of a model come together under different circumstances. For example, you might want to:
- Use different models and model hyperparameters
- Use different training or evaluation data
- Run different code (including small code changes that you want to test quickly)
- Run the same code in a different environment
ML Models are machine learning algorithms that generate predictions from data. As an ML Engineer, you definitely want different versions of ML model artifacts to be able to search and discover through a data discovery solution.
ML model metrics. Model evaluation metrics (like accuracy, precision, recall, specificity, log loss, and other scores) are used by ML Engineers to evaluate how their models perform. They are crucial for any data science project, and serve as a guiding light in helping to understand what direction to take next.
Data for ML model inferencing. Inferencing is the process of using a trained algorithm on new data to drive predictions. Just as with training and testing data, you also need to discover data for the inferencing stage, and make sure it fits your requirements.
Feature Stores. Feature store is a data warehouse that ingests feature data from different sources after it has been transformed, aggregated and validated. Data from feature stores can then be used for model training and inferencing stages.
How Integrated ML Workflow, Data Discovery and Observability can Benefit Data Teams
The typical workflow of an ML engineer goes through the following steps: search what data exists in an organization, evaluate that data against the project and define its quality, get proper access to the data, use it to run experiments, pick the best hypothesis, run ML model training on the data in Kubeflow, register the model with a model registry, and connect it to feature store to ensure proper inferencing.
When an ML engineer embarks on a project, it is important to operate high-quality, reliable data in each of these steps. Even when a model is ready and deployed, it completely depends on the underlying data. If data breaks, so does the model. Changes that may seem harmless at first glance, like slight shifts in distribution or minor data lateness, have the potential to quickly snowball into major issues.
Open Data Discovery Platform for ML and Data Engineers
In thinking about the above-mentioned issues, we developed a solution with ML and Data Engineers in mind. ODD Platform is the first open-source data discovery and observability platform. It fills the missing parts of data discovery to allow ML engineers to easily find all entities that are a part of their ML workflow. It also helps data engineers to discover everything they need for data engineering.
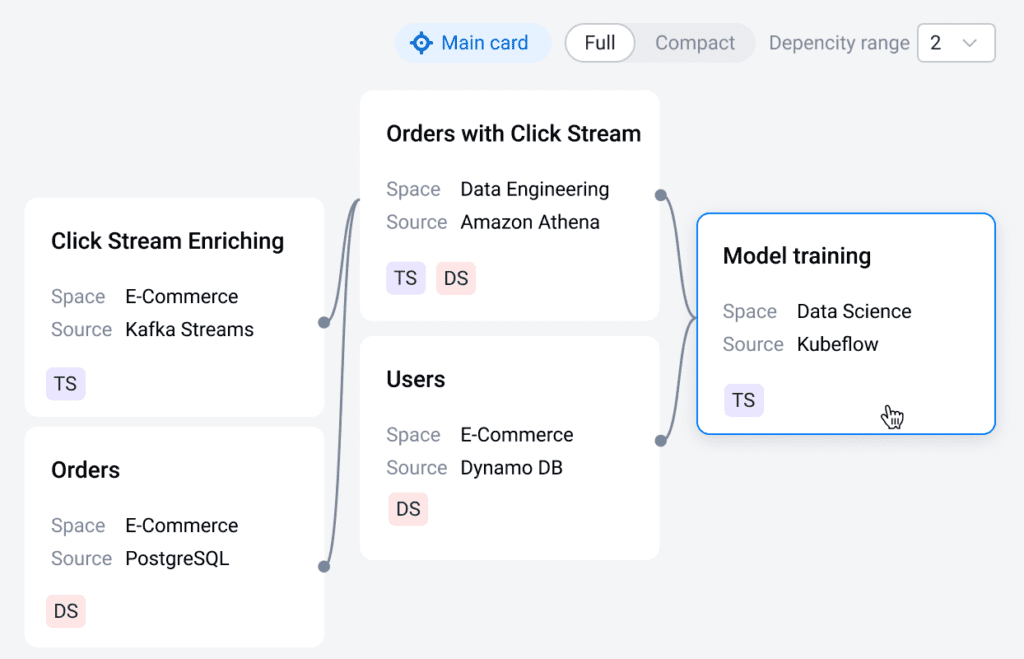
ODD automatically collects metadata from all connected data sources (including ML-specific ones) and registers them for the lineage. The lineage section of each data product shows all its upstream and downstream connections. If something changes in the data that ML engineers use for their ML models, lineage and rich alerts will help them proactively find the root cause of the issue in a matter of minutes, instead of hours or days. All owners of affected data products will be immediately notified of changes.
ODD Platform is based on Open Data Discovery Specification – an open-source, industry-wide standard for metadata, designed to establish rules for how metadata should be collected, processed, and managed in an automated manner.
Unlike existing data catalogs and other data observability tools, ODD does not require any paid or complex infrastructure. The deployment process is as easy as it gets. The only difficult requirement is having PostgreSQL. ODD runs as a cluster of microservices, and you can easily add or remove data sources from your setup.
ODD is licensed under the Apache 2 license. The team has committed to staying forever open-source, and to building the product in public without any hidden agenda.
Conclusion
Data quality is crucial for building sustainable and reliable ML models. To have relevant, reliable and readily available data at hand at all times, ML engineers need a data discovery and observability system that operates ML entities as first-class citizens, to provide company-wide data discovery, quality assurance, and transparency.
Such a tool would remove barriers that currently exist between data engineers and data scientists, and facilitate collaboration. It would end the disconnect that people in those roles currently experience, and make them fully aware of the other’s part of the data pipeline.
ODD Platform is the first open-source data discovery and observability platform for ML engineers that offers a solution to the set of issues discussed in this article. Following are the main use cases it can help with:
- Onboarding of new ML Engineers and other data professionals
- Data discovery for ML engineers and other data professionals
- Fully end-to-end data observability and alerting for data pipelines
For more information about ODD Platform, please check out our organization opendatadiscovery and the main repository odd-platform on GitHub.
{kind=link}