

There are different ways to define common sense machine learning. It could mean using simple models whenever possible, avoiding overfitting, correctly selecting features, or doing cross-validation the right way. Or it could mean not using any data set. Yet, making predictions far outperforming those from smart teams of data scientists working on large data sets. The first definition may be the topic of a future article. Here I focus on the latter. I provide examples to illustrate what I mean. In general, it boils down to having the wrong data and/or lack of business experience, or lack of common sense. I requires out-of-the-box thinking.
Bigger teams of top-caliber data scientists, bigger data, and better models are not the solution. More diversified data, or third-party data, sometimes helps a lot. The issue is how to find the right data. Though in some cases, no data is necessary: I call it machine learning performed with the human brain alone.
First Example: Covid Predictions
In the early days, when I was looking at statistics about “recovered people”, the number was incredibly low. After further digging into this, it became clear that “recovered” means you tested positive and your case was recorded in some official database. Maybe you went to a hospital and were discharged “alive”. None of my infected family members and close friends — all recovered on their own — ever made it to the statistics. This was my starting point to further investigate how far off the official numbers might be.
Today, scientists complain about too few people getting tested, or testing at home and not reporting the results. Some make claims that for any official positive case, 14 are unreported. Whether tracking cases is still important or not is an issue that I won’t discuss. I would think hospitalizations to be a better indicator, though it is a lagging one. Scientists use wastewater data these days, though it is not tracked evenly across the US.
A simple solution
In the last few days, I was sick and still recovering. I don’t know what it is, my wife (somewhat sick too) tested negative for Covid. A few colleagues in her school got Covid very recently. I did a Google search on how long Covid fever can last. And that led me to a simple solution to estimate cases trending, and include those (like myself) that never make it to the official databases.
I came up with this idea: look at Google keyword trends for “Covid symptoms” or related keywords. You can break it down by area. If you have access to the full data (Google does), you should even be able to tell, based on the IP address, that I googled “Covid fever” yesterday. Of course, it does not mean that I am positive, but this is a good proxy metric. In particular, I’ve found that the situation in Oregon is “worse” than in nearby states. Below is the picture. The data is free to everyone, and available here.
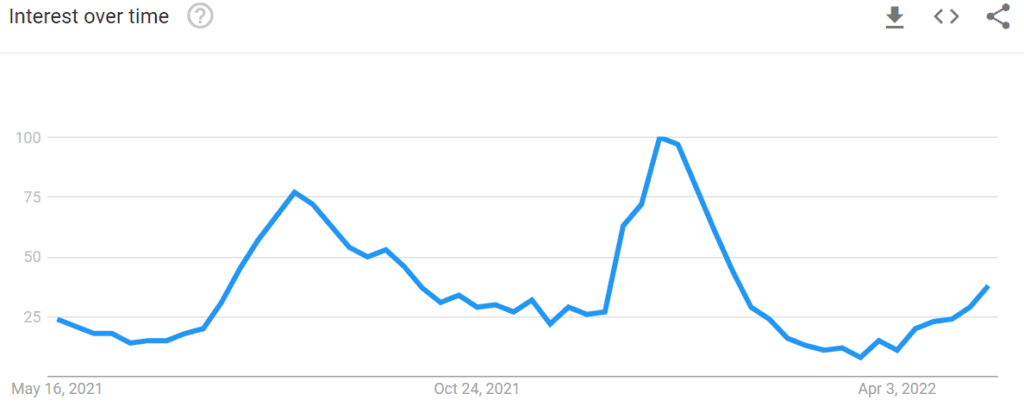
You also start questioning whether to vaccinate when you probably just got infected. The vaccine may be outdated, and as expected, I am not sicker than vaccinated people catching the virus. If you experience difficulty breathing (I did not this time), and you self-isolate, you also wonder why to wear a mask at home. It could make a situation already unpleasant, worse. There does not seem to be any serious study on this. A one-size-fits-all solution is far from ideal. My point is that some basic statistics are missing from many analyses.
Second Example: The Invisible Candidates Responding to Your Job Ads
I recently wrote an article about the myth of talent shortage, when recruiting data scientists: see here. The automated resume screening process used by many companies is poor AI. Candidates can list 6 programming languages to get through, and honest, good candidates may fail.
Good hiring managers know how to reach out to potential candidates on LinkedIn. And since I resumed being very active on LinkedIn, so has the number of recruiters contacting me, even on Facebook! It is easy to post comments that are much deeper than what many people post, and shine. I don’t do it to find a job, but to grow my audience. In the end, I am wondering if the concept of a resume, is becoming obsolete.
Hiring managers relying too much on resume screening tools such as black-box systems are at a disadvantage. You need to work a little harder. I imagine these tools will get smarter in the future, but for now, they are not great. Do this simple test: apply with made-up resumes to your own advertised positions. See how many of these resumes go through. Then your next question is: should my company stop wasting money on such an inefficient system?
Talking about hiring, you certainly want people with business knowledge (see next section about this). Much of common sense lacking is actually a lack of business knowledge. This may be as important as being a good programmer. Yet, when NBCi hired me to work on advertising attribution problems, my business expertise in TV advertising was zero. I never watch a TV show and don’t have a TV set. But they eventually liked what I did because I explained it in simple words and simple spreadsheets, that stakeholders could understand. It also produced added value. One thing to consider when interviewing a candidate, or applying for a position: discuss past success stories.
Third Example: Missed Revenue Opportunities for Companies Like Reddit
One recurrent problem that I experienced recently is my Ads having a high rejection rate on platforms such as Facebook, Twitter, or Reddit. It is as if I was selling something illegal. Yet they are highly targeted, relevant, and promote high-quality machine learning papers. On the contrary, when I visit these platforms, I only see irrelevant ads.
I am also a professional Ad writer. Initially, I thought that Ads are approved by robots. Yet in many cases, it is by human beings. If the people manually checking these ads can’t detect what’s good from bad, how could AI ever do it? Some AI systems are designed by people with very little knowledge about the actual problem. They may have a Ph.D. in machine learning from MIT, but either they lack business knowledge or the people above them don’t know what they are doing. In the case of Reddit, I asked them to write an Ad that would be accepted. They haven’t been able to deliver. This was to advertise MLTechniques.com. Hopefully, with the IPO coming soon, there are going to be more people who care about revenue — at least the shareholders.
As I wrote in the previous section, I worked successfully in TV advertising without knowing anything about TV programs and was unable to operate a TV set. So it is definitely possible. But knowing your customer experience goes a long way to improve your AI. If companies like Reddit hired machine learning scientists who are advertisers themselves, they would gain the client’s perspective to develop more meaningful AI. Right now, customer experience and Ad approval are probably done by two different teams. Either they don’t communicate, or have conflicting goals.
Other Examples
Automated translations on Facebook is another example. Despite the fact that I read and post in French on Facebook regularly, its algorithms have decided that I am monolingual. FB translates everything in English for me, probably because I am located in the US. The engineers who developed this feature must face the same problem when on FB. And the English version can be funny. Google also asks me time and over if I need translation to English. Yet, I haven’t used this feature a single time in years. These are just little annoyances, but it shows that those who designed these systems (or those making the final decisions on the features) don’t live in the real world.
Other example: Google maps brought me on some awkward roads. On a multi-day car trip in remote areas, the algorithm is brutally mathematical. It sure shows the fastest or shortest way. But it does not care about long sections of 2-lane roads infested with tractors, or long stretches without gas stations, when it is easily avoidable. If you split your trip in shorter sections, it does a much better job though — an easy fix that you would think the algorithm itself could take advantage of. You are wondering if the people who designed these systems, ever tested them other than for your run-of-the-mill commute. The algorithm feels mathematically optimized in some way. But not in the way that is most useful for practical purposes, as soon as you use it for non-standard trips.
Finally, the collapse of the housing bubble in 2008, is an example of data science gone wrong. Did the scientists followed their models, the way the captain of the Titanic followed his boat to the abyss? Or were they smart enough to avoid losing money? That is, not too greedy?
About the Author
Vincent Granville is a machine learning scientist, author, and publisher. He was the co-founder of Data Science Central (acquired by TechTarget) and most recently, the founder of MLtechniques.com.
{kind=link}