
These days, it is as if AI is just about GenAI (generative AI), LLMs (large language models) and very large models. It has eclipsed computer vision, voice AI and everything else. Part of the success of trillion-parameter models is that they are over-parametrized. That is, many different parameter combinations lead to good enough solutions. In short, with enough hidden layers and GPU time, you are likely to stumble upon impressive results. No one really knows why it works like that, but it works.
I also observed a similar phenomenon with some of my methods that do not rely on neural networks. They work best when granularity is maximum. Those that rely on combinatorial resampling, do well with only a few million iterations, exploring only a tiny fraction of the sample space. The performance is especially remarkable in high dimensions, where you expect combinatorial methods to fail. The success is due to smartly leveraging the sparsity of the feature space. Without this, you would need a lot more than 10100 iterations, making these methods impossible to implement.
Modern LLMs are not the Panacea
Despite the performance, my experience with OpenAI (GPT) is disappointing. It does better than most alternatives, but it does no address my needs. In my case, I am looking for answers to research questions. But GPT won’t share the references that it uses to answer my prompts, even when asked to do so. My issues – shared by many – are best described in my recent LinkedIn post, “My New LLM Project”, here.
As the title suggests, I will have to create my own tool. Maybe because OpenAI is afraid to reveal sources subject to copyrights. In addition, GPT answers are very wordy and assume that the user is a beginner. Yet, I only need a few bullet points and some links. I don’t have time to browse the lengthy yet mostly rudimentary output written in nice English. Thus, my solution will be far easier to implement (no neural network, no beautiful English) and serve me and others a lot better. All this thanks to using the right sources that specialize in one particular area: mathematics, in my case.
Research Topics Besides LLMs
You don’t hear much about new developments outside the hot topic of the day: LLMs. Part of the reason is that they receive less funding and attention. But things are starting to shift, with an increasing interest in solutions that require less GPU and cloud time. In short, solutions that are much less expensive.
Some of my research focus on just that: faster techniques – by several orders of magnitude – delivering better results. In the process, designing much better evaluation metrics, not subject to false negatives (results rated as good when they are bad). This frequently happens when generating tabular synthetic data. Then, methods that generate data outside the observation range, leading to replicable and explainable results, and less sensitive to the choice of the seed. Much of this research with case studies, can be found on my blog, here.
What Happened to Traditional Machine Learning?
It is not dead. For instance, some of my research still deals with topics such as resampling or regression. But it has nothing to do with what you find in the most recent textbooks or courses on the subject. I brought these old topics to a whole new level. In some cases, it is integrated in GenAI technology.
My “cloud regression” technique does not have a dependent feature (the response). It performs supervised and unsupervised regression, or clustering, under a same umbrella. What’s more, it performs any kind of regression you can think about, including regularization methods: Lasso, ridge, and so on. Be it on a line (linear regression), ellipse, or a combination of multiple arbitrary shapes in any dimension. And it is model-free, even to compute multivariate confidence bands. My loss functions do not rely on probabilistic arguments, making them more generic even compared to those used in modern LLMs. Even the gradient descent method is original, now math-free and parameter-free, without learning parameters. After all, your data is not a continuous function: there is no need to bring calculus into it.
New Types of Visualizations
Another traditional research area is data visualization. While most people focus on dashboards, I designed new, powerful visualizations that summarize complex, high-dimensional data with 2D scatterplots. Then, my most recent visualization is a special type of data animation useful in many contexts, GenAI or not.
To illustrate how it works, I tested the above cloud regression procedure on 500 training sets, when the shape is an ellipse. I generated each training set with a specific set of parameters and a different amount of noise. The goal is to check how well the curve fitting technique works depending on the data. The originality lies in the choice of a continuous path in the parameter space, so that moving from one training set to the other (that is, from one frame to the next in the video) is done smoothly, yet covering a large number of possible combinations. The blue curves below are the estimates of the unknown, theoretical ellipses.
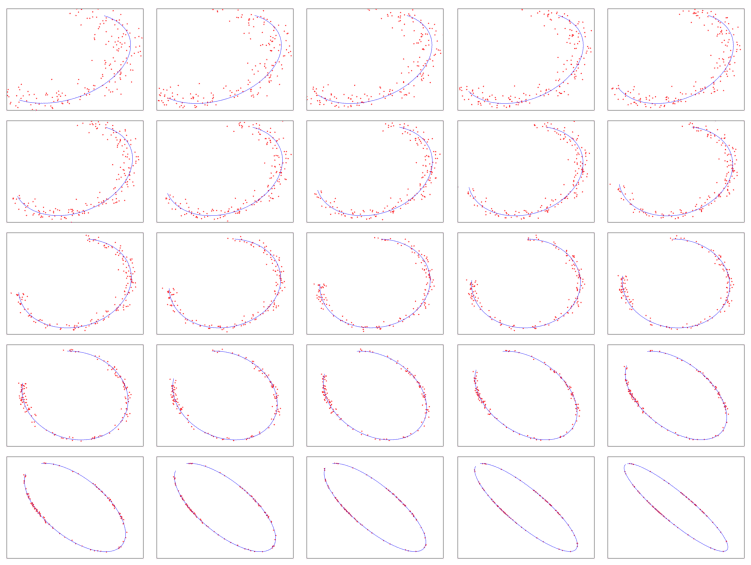
See 25 of the 500 video frames in the above figure. Note how the transitions are smooth, yet over time cover various situations: a changing rotation angle, training sets (the red dots) of various sizes, ellipse eccentricity that varies over time, partial and full arcs, and noise ranging from strong to weak. You can watch the corresponding 25-sec video on YouTube, here. The source code both for the curve fitting and video production, is on GitHub, here.
Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET.
Vincent is also a former post-doc at Cambridge University, and the National Institute of Statistical Sciences (NISS). He published in Journal of Number Theory, Journal of the Royal Statistical Society (Series B), and IEEE Transactions on Pattern Analysis and Machine Intelligence. He is the author of multiple books, including “Synthetic Data and Generative AI” (Elsevier, 2024). Vincent lives in Washington state, and enjoys doing research on stochastic processes, dynamical systems, experimental math and probabilistic number theory. He recently launched a GenAI certification program, offering state-of-the-art, enterprise grade projects to participants.
{kind=link}