

The ability of Generative AI (GenAI) tools to deliver accurate and reliable outputs entirely depends on the accuracy and reliability of the data used to train the Large Language Models (LLMs) that power the GenAI tool. Unfortunately, the Law of GIGO – Garbage In, Garbage Out – threatens the widespread adoption of GenAI. Whether generating management reports or developing machine learning models, our analytical results’ accuracy, quality, and reliability are inherently connected to the accuracy, quality, and reliability of the underlying data.
GenAI tools have unbelievable superpowers, such as generating realistic images, writing engaging texts, composing original music, writing software code, researching operational problems, and more. Unfortunately, just like Superman has a weakness to kryptonite, AI models have a weakness to poor data quality. Poor data quality can degrade AI models’ performance and produce unreliable or harmful outcomes. For example, if an AI model is trained on data that contains biases, errors, or inconsistencies, it will generate outputs that have biases, errors, or inconsistencies. This can lead to severe consequences, such as discrimination, misinformation, or loss of trust.
Data quality is the kryptonite of AI models, and we must put data quality front and center when creating GenAI applications. Otherwise, we might end up with a Superman who is not so super.
And while data quality is a problem for which every industry must contend, nowhere are the ramifications more dire than in healthcare.
Reengineering of Patient Health Data
Researching the following question: “What percentage of Patient Health Records are populated with inaccurate data because nurses, doctors, and administrators have re-engineered the data due to insurance and liability reasons?” yielded some disturbing results.
Studies have suggested that this practice may be more common than expected and can negatively affect patient safety and quality of care. One study from 2018 found that 28% of nurses admitted to altering patient records to avoid blame or litigation, and 31% said they had witnessed their colleagues doing the same. Another study from 2019 reported that 18% of physicians had deliberately manipulated or withheld clinical information in the past year to increase their reimbursement or reduce their liability. These findings indicate that data re-engineering is not a rare phenomenon but a widespread and systemic issue in healthcare.
Data re-engineering can affect the accuracy and completeness of patient health records, leading to errors in diagnosis, treatment, billing, and reporting. For example, if a nurse documents a patient’s vital signs as normal when they are abnormal, this could delay detecting a severe condition or complication. If a physician codes a patient’s diagnosis as more severe than it actually is, this could result in over-treatment, unnecessary tests, or higher charges.
Data re-engineering to avoid insurance payment and legal liability issues can significantly hinder the applicability of leveraging AI to deliver better patient outcomes, more reasonable prices, and an improved health worker environment that can transform the healthcare economic value curve (Figure 1).
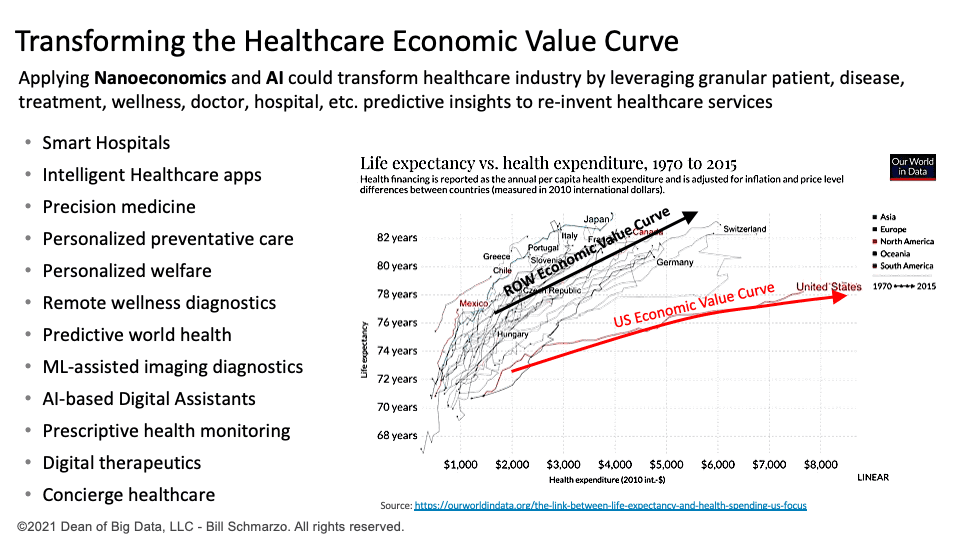
Figure 1: Healthcare Economic Value Curve
And it isn’t just the healthcare systems that must deal with re-engineered and distorted data. Using AI in judicial decisions can yield inaccurate and unreliable outcomes due to distortions in the data introduced by plea bargaining.
Plea bargaining involves defendants pleading guilty to lesser charges or reduced sentences. Plea bargaining can skew the official records of crime, conviction, sentencing patterns, and recidivism rates and significantly impact the AI models’ abilities to deliver meaningful, relevant, responsible, and ethical outcomes.
Fixing the Data Quality Problem
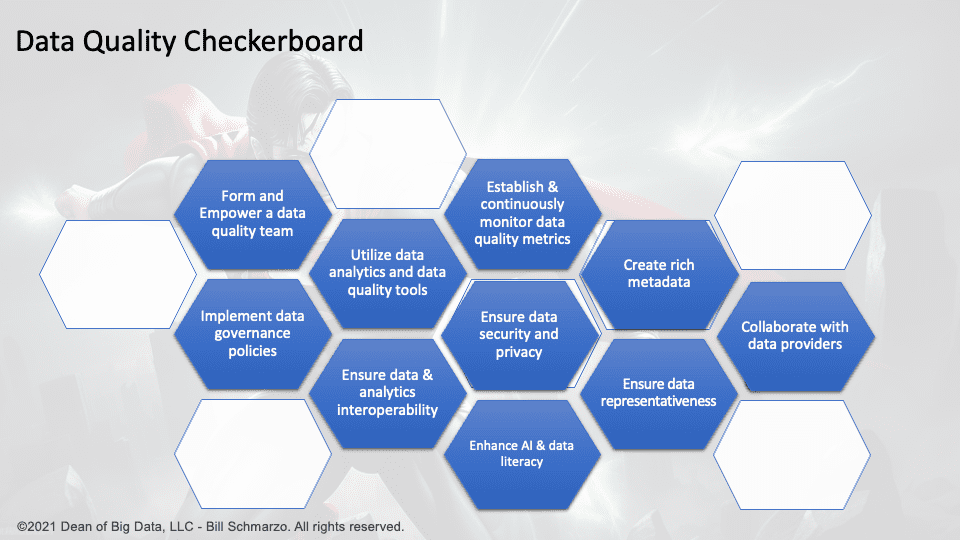
If Data Quality is the kryptonite to our AI aspirations, there are ten actions that an organization can take to address the data quality problems that render AI models inaccurate, unreliable, and powerless:
- Implement data governance policies. A robust data governance framework should be in place to define data quality standards, processes, and roles. This helps create a culture of data quality and ensures that data management practices are aligned with organizational goals. Define ownership, accountability, and responsibility for data quality across the organization.
- Utilize data analytics and data quality tools. There are many tools available that can help detect, measure, and resolve data quality issues. These tools can automate data cleansing, validation, transformation, and enrichment tasks.
- Form and Empower a data quality team. A dedicated team of data quality experts should oversee and execute data quality initiatives. The team should collaborate with other stakeholders, such as data owners, providers, users, and analysts.
- Establish and continuously monitor data quality metrics. Data quality metrics should be defined and tracked to measure the performance and impact of data quality efforts. Collect user feedback, conduct audits, apply corrective actions, and use data quality processes and tools to automate data cleaning, validation, enrichment, and monitoring.
- Ensure data representativeness. Data diversity and representativeness refer to the extent to which the data reflects the real-world phenomena and populations the AI models aim to capture and serve. They should be ensured by collecting and analyzing data from various sources, domains, and perspectives.
- Ensure data security and privacy. Protect the data from unauthorized access, use, modification, tampering, or disclosure. Implement appropriate policies and technologies to encrypt, anonymize, or mask the data as needed. Comply with the relevant laws and regulations regarding data protection and consent.
- Ensure data and analytics interoperability. Enable the exchange and integration of data and analytics across different systems. Data and analytics interoperability can facilitate the sharing and collaboration of data and analytics across various stakeholders in identifying and addressing data quality and data inconsistency problems.
- Create rich metadata. Provide clear and accurate information about the data sources, definitions, formats, methods, assumptions, limitations, and quality indicators. Use standardized and consistent terminology and formats for the data documentation and metadata.
- Collaborate with data providers. Collaborate with critical data and application providers in addressing data quality problems at the source. They should be involved in ensuring data quality by providing clear documentation, metadata, and feedback mechanisms.
- Enhance AI & data literacy. Data literacy and education are the skills and knowledge required to effectively understand, use, and communicate with data. They should be enhanced by providing training, guidance, and best practices to all levels of the organization.
Leveraging AI / ML to Help with Data Quality
One of the most significant data quality opportunities is using AI / ML to automate identifying and resolving data quality problems. This includes:
- Duplicate detection: ML can identify and remove duplicate records in a dataset, such as customer profiles, product listings, or invoices. For example, an ML model can learn to compare different records based on their attributes, such as name, address, email, phone number, etc., and assign a similarity score to each pair of records. If the score exceeds a certain threshold, the records are considered duplicates and can be merged or deleted.
- Outlier detection: ML can help detect and correct values significantly different from the rest of the data, such as typos, errors, or anomalies. For example, an ML model can learn to identify the normal range and distribution of values for each attribute in a dataset, such as age, income, temperature, etc., and flag any values that fall outside the expected range or deviate from the pattern. These values can then be verified or replaced with more reasonable ones.
- Missing value imputation: ML can help fill in the gaps in a dataset where some values are missing or unknown, such as survey responses, sensor readings, or ratings. For example, an ML model can learn to predict the missing values based on the available values and their relationships. This can help improve the completeness and accuracy of the data.
- Data enrichment: ML can help enhance and augment the data with additional information or features not present in the original dataset, such as geolocation, sentiment, category, or recommendation. For example, an ML model can add relevant information from external sources like web pages, social media, or public databases. This can help increase the richness and usefulness of the data.
!! Important Message to Data Quality Advocates !!
Data quality advocates have a once-in-a-lifetime opportunity to make their data quality message compelling to senior business executives. Given the untold business potential of AI, business leadership is finally willing to listen to a plan that improves data quality and unleashes the economic power of AI.
But if your message is only about data quality, then your message and mission will fail. Instead, make the conversation about value creation and then highlight data quality’s role in delivering value.
Remember, data quality is an end to their value creation means in ensuring that their AI models deliver meaningful, relevant, responsible, and ethical outcomes.
Data Advocates, your day has finally come!
{kind=link}