
If you are employed as a data scientist and have survived (or strived!) in your position for more than a year, chances are you are at least a good data scientist. This is particularly true if you were promoted. The difference between a mediocre and a good data scientist will be the topic of a future article. I decided to write this article after reading a viral post on LinkedIn, entitled “10 differences between amateurs and professional analysts”. The author, Cassie Kozyrkov, is Chief Decision Scientist at Google. I start with Cassie’s list, and then add my own suggestions.
Cassie’s List
Here is her top-10 list, in her own (probably random) order:
- Software skills
- Handling lots of data with ease
- Immunity to data science bias
- Understanding the career
- Refusing to be a data charlatan
- Resistance to confirmation bias
- Realistic expectations of data
- Knowing how to add value
- Thinking differently about time
- Nuanced view of excellence
My List
The skills, competences or experiences of a great freelance data scientist cover different categories. I break down my list according to these categories. Some overlap with Cassie’s list.
Optimizing your time
Optimize your time to produce value faster. This sounds like a machine learning problem in itself. But there are a few rules of thumb.
- Know the 80/20 rule: don’t seek perfection, seek “good enough” models. Your data is not perfect anyway. By following this rule, you can handle multiple projects faster.
- Automate data exploratory analysis. Spend little time on coding and data cleaning at this stage. Instead, this should be a streamlined process, started and completed with one click most of the time.
- Don’t re-invent the wheel. Write reusable code, and use Python or other libraries when possible. Document your code properly. Use variable names that have real meaning, even if they are long. Organize your material in folders, on the cloud (so it will survive a laptop crash). Increase time spent on documenting. Some well paid, highly valued Google engineer went as far as to outsource and pay people in India, to do part of his job. I strongly advice against doing this, as your company data and technology is private.
- Don’t underestimate Excel. Some analyses, even advanced analytics, can be done in Excel. Also, non-tech people are familiar with Excel. So you can share your full analysis with various teams, such as sales, product or marketing. Make sure there is one summary tab in your spreadsheet, named (say) “dashboard”. That way, non-tech people won’t waste too much time on your spreadsheet. It will also help you when you look at your spreadsheet 6 months down the line.
Optimizing other people’s time
Management will appreciate you if you follow these rules. The reward is bigger than from using stellar algorithms. Remember, time is money.
- Understand what management is really trying to solve. This will reduce the number of meetings and iterations required to solve the problem. And the chances of working on a project going nowhere, are smaller.
- Discover opportunities to add value. Management may not be aware of the unlocked potential of company data. Be proactive by suggesting low hanging fruits, rather than reactive.
- Embrace simplicity, explain things in simple words. Use simple models whenever possible: they are easier to explain, and more convincing. These days, management people love explainable AI more than obscure black-box systems. It also has a positive impact on risk reduction.
- Design powerful charts and visualization. A good image is worth a thousand words. A good, short data animation (video or even a Gif image) is worth many images. And these days, they are easy to produce, without any coding. See my example in Figure 1.
Data and model acumen
You can acquire these skills, like any other skill in my list. Some people seem to be born with them. They are called talented. If you survive long enough in your line of work, you will eventually acquire them automatically. But it is better to start early, for faster career growth. You can call them analytic acumen.
- Assess the real expected potential and variability of your model or predictions. Under-promise, but over-deliver. Don’t hesitate to mention potential defects or weaknesses. However, strike the right balance: don’t scare the stakeholders by asking too much time to refine your analyses, unless justified. In some cases, re-starting an analysis from scratch is more efficient than trying to fix it.
- Look for missing data or external data sources. In the early days of Covid, most people were not tested. Many recovered on their own. The number of “recovered” people was hugely underestimated. Common sense worked better than the most sophisticated analyses, to make predictions. And it requires much less time and resources. These days, the unobserved data in question is captured through virus measurements in waste water.
- Blend multiple algorithms rather then opposing them to each other to find a winner. Some algorithms work better on some observations, and not so well on other observations. A decision assigned to an observation can be the result of a vote among multiple competing algorithms. Such blending is known as ensemble methods.
- Perform sensitivity analysis on your data set: add noise to the data, play with synthetic data, perform simulations. See how your predictions are sensitive to noise or erroneous data. Master feature selection and cross-validation techniques.
- Don’t forget model maintenance. Some tables, parameters, or rules change over time. Because data change over time. Beware of hybrid data. Data coming from different vendors (or from the past) may have similar fields. But they may be measured differently.
Code-specific advice
- Find bottlenecks in your code. Think of how to make your code run faster.
- Let your code generate warning and error messages emailed to the right person (for instance: “empty data set”, or “matrix determinant close to zero”).
- Let your code produce a log of activity and summary tables updated in real time. That way, if the program or server crashes, your program can be resumed from where it stopped, without data loss. Your algorithm can be designed with that feature in mind.
Getting community feedback
I included here two items that are sometimes overlooked.
- Publish and share what you can with the community. GitHub and some social groups are great platforms to get feedback and recommendations. For instance, your vendor community blog, reddit.com/r/MachineLearning or Quora, depending on the topic.
- Learn, learn, learn. Online classes is one option. If you are a self-learner, spend time reading what others are doing. You need great search skills for that, and using the right search engine. In my case, StackExchange more so than Google. When designing my shape classifier, googling “shape classification” was of no use. But “shape classification machine learning” led to interesting results.
Example
The following picture summarizes many of the concepts discussed here. It comes from Excel, and I used free online tools (EZgif.com) to make the Gif image without writing any code. It took very little time. This animated Gif is a summary of model performance. I designed it almost as a sales pitch (it’s actually free, but I want people to look at it). Also, I researched the idea on Google, and found several articles. This helped me avoid some of the drawbacks discussed in the literature. Finally, the technique belongs to explainable AI, and leverages synthetic data. You could improve the picture by using meaningful words (“correlation”) rather than Greek letters, for core performance indicators.
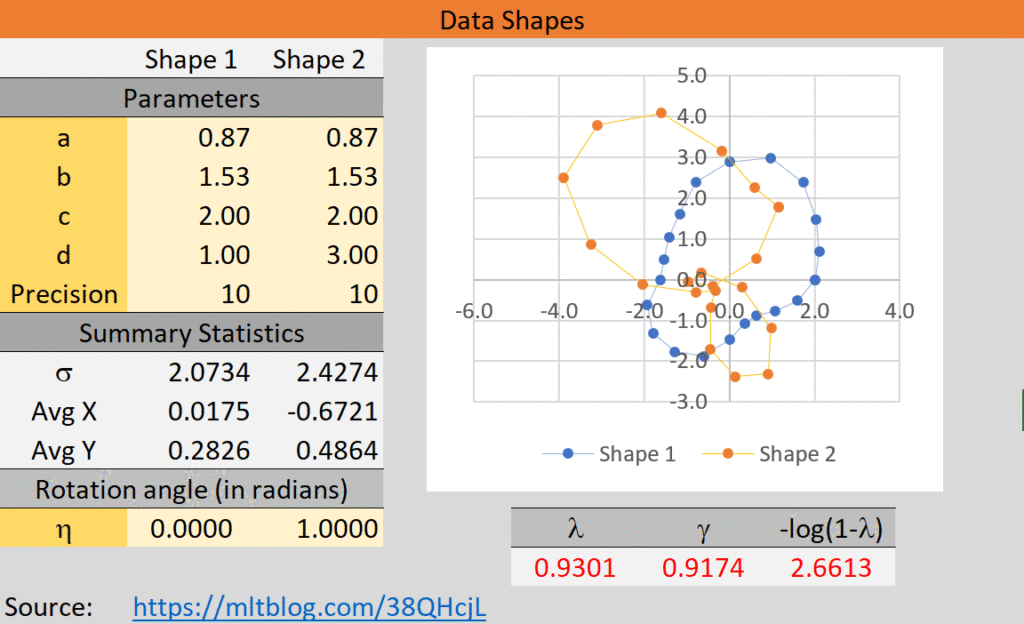
You can find the spreadsheet in question on my GitHub repository, here. The picture is on the “Dashboard” tab. For explanations, read this article. The Gif is properly rendered in that article: it features eight pairs of shapes over a 40 second time period. You can turn it into a video (MP4 file) in one click, using the same platform EZgif.com. Sharing what you can on the cloud, was one of my advices. You can grant access to selected people, it does not need to be fully public.
About the Author
Vincent Granville is a machine learning scientist, author and publisher. He was the co-founder of Data Science Central (acquired by TechTarget) and most recently, founder of MLtechniques.com.
{kind=link}