

Named entity recognition or NER is popularly used in NLP tasks in machine learning models. In the world, where textual information is generated every millisecond around the world across fields, approaches such as named entity recognition have been in practice for more than a decade. Natural language processing deals with an understanding of a number of languages spoken and written by humans, wherein, basic tasks are basic NER models, which provide much-required data classification and interpretation help.
Named entity recognition concerns specifically labeled entities in machine learning training data; POS tagging and syntactic chunking are commonly followed while performing specified NLP tasks. Several predictive content and content discovery engines on various online platforms for diverse business verticals utilize NER, day in and day out.
How named entity recognition is applied
Named entities can be of various types. The types of data that are processed and then applied may include a wide number of categories. For example – Name, Unit, Type, Quantity, Country, Occupation, Ethnicity, etc. The entity type depends on the type of natural language processing requirement, which mainly involves relation extraction, information extraction, coreference resolution, and question generation.
Typical process followed in NER
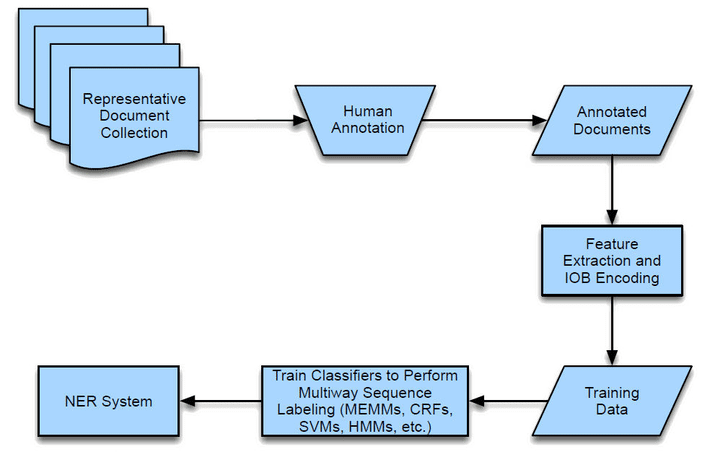
Image credit: Devopedia
The challenge of extracting meaningful information from unstructured data is nothing new. While implementing this for content discovery and in predictive content tasks, ambiguity remains a key challenge that can divert the recognition process. Multi-token entities and names within names make the approach difficult often. In such scenarios, coreference resolution helps in resolving this challenge. Coreference resolution finds the clusters with linguistic similarities to remove textual ambiguities in the content. As supervised learning tasks, it is based on content discovery patterns required labeled machine learning data. Making the underlying named entity system work, labeled data quality is equally crucial.
Important milestones in NER approaches
A logic applied by a researcher using heuristics, exception lists, and extensive corpus analysis in 1991 led to the discovery of named entity recognition. Starting then, various other NER-focused techniques combined with other machine learning principles have been adopted.
Since then a number of incorporations surrounding the technique have surfaced. Some prominent are the ones containing algorithms having K-Nearest Neighbor (KNN) classifier and Conditional Random Field (CRF) labeler for establishing the context in the text, from both macro and micro levels. And utilizing the basis of NER into a more advanced form of textual information extraction with Transformer Encoder, which uses relative positioning and takes distance and direction into consideration as well.
NER in online content discovery
Anything that is related to exploring different types of content should be attributed to content discovery. The content is primarily textual and often attributed to video-based aspects for search, as well. For instance, the recommendations on video streaming apps. Content discovery can be regarded as a process as well, owing to the multitude of technological processes it utilizes for making personalized content available to users worldwide.
Content is an integral part of the online ecosystem. From online publishers and web portals to over-the-top platforms all are driven by exclusive content. NLP techniques like this are enabling search engines and recommendation systems with sorting and displaying relevant content to suitable audiences. For opinion mining and Semantic web-based content searches and presence, named entity recognition is in wide usage already. The majority of content recommendation or predictive engines work on classifying text with the help of machine learning models (support vector machines, KNN and NB classifier and then further, dissecting the choices on Topic Modeling methodology of LDA (latent Dirichlet allocation) and applying to extract semantic and syntactic features of the content.
Content recommenders primarily focus on user content choices based on the search keywords they enter, the user history, and associated metadata available for mapping. The platform, however, can vary; the process of the recommendation will be less likely to be different in the case of recommendation. In predictive content recommendations, the NER system will offer users with options based on parameters largel…, which is prepared as per labeled data applied through machine learning models. Therefore, the entire cycle of content discovery is backed with textual content extracted through ML models. The named entity approach, thus, has powered many popular digital content-driven platforms such as Netflix. It has actively helped in resolving multiple content mining cases for social media platforms such as Twitter.
EndNote
Content being the chief ingredient of digital platforms, will continue to rule. For Natural Language Processing tasks like named entities, finding precise information has become feasible.
{kind=link}