Home
Articles


How to implement big data for your company

Big data analytics empowers organizations to get valuable insights from vast and intricate data sets, offering a pathway to improved decision-making, excellent performance, and competitive… Read More »How to implement big data for your company
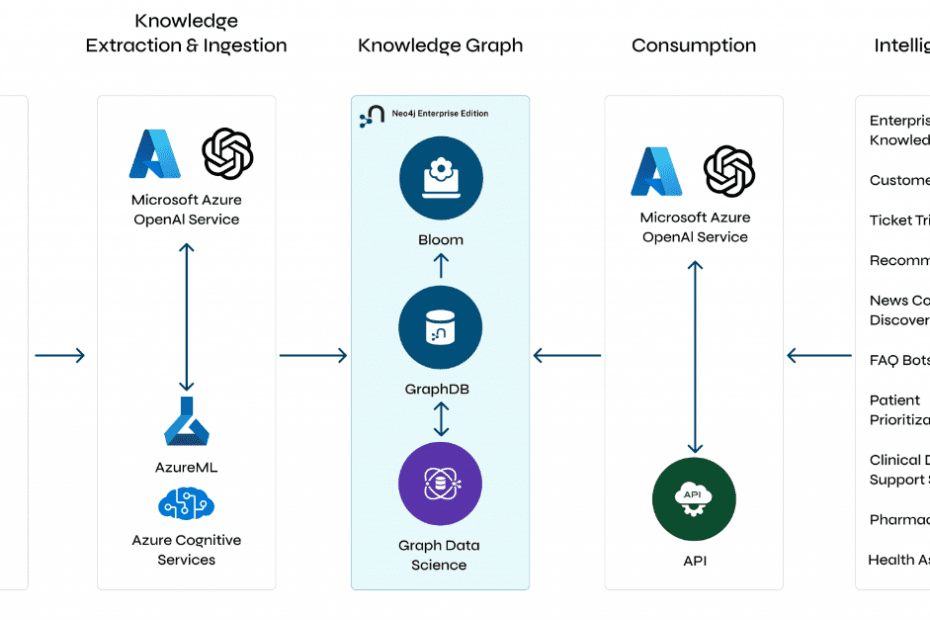
Understanding GraphRAG – 2 addressing the limitations of RAG

Background We follow on from the last post and explore the limitations of RAG and how you can overcome these limitations using the idea of… Read More »Understanding GraphRAG – 2 addressing the limitations of RAG

How predictive analytics improves payment fraud detection

Payment fraud is a significant issue for banks, customers, government agencies and others. However, advanced predictive analytics tools can reduce or eliminate it. Minimizing false… Read More »How predictive analytics improves payment fraud detection
Understanding GraphRAG – 3 Implementing a GraphRAG solution
In this third part of the solution, we discuss how to implement a GraphRAG. This implementation needs an understanding of Langchain which we shall also… Read More »Understanding GraphRAG – 3 Implementing a GraphRAG solution

Quantization and LLMs – Condensing models to manageable sizes

The scale and complexity of LLMs The incredible abilities of LLMs are powered by their vast neural networks which are made up of billions of… Read More »Quantization and LLMs – Condensing models to manageable sizes

Diffusion and denoising – Explaining text-to-image generative AI
The concept of diffusion Denoising diffusion models are trained to pull patterns out of noise, to generate a desirable image. The training process involves showing… Read More »Diffusion and denoising – Explaining text-to-image generative AI

How data impacts the digitalization of industries

Since data varies from industry to industry, its impact on digitalization efforts differs widely — a utilization strategy that works in one may be ineffective… Read More »How data impacts the digitalization of industries

Using window functions for advanced data analysis

Window functions are an advanced feature of SQL that provides powerful tools for detailed data analysis and manipulation without grouping data into single output rows,… Read More »Using window functions for advanced data analysis