

One of the best known examples of GPT-3 for developers is the Github co-pilot
Trained on billions of lines of public code, GitHub Copilot is more than autocomplete of code. GitHub Copilot is powered by Codex, the new AI system created by OpenAI.
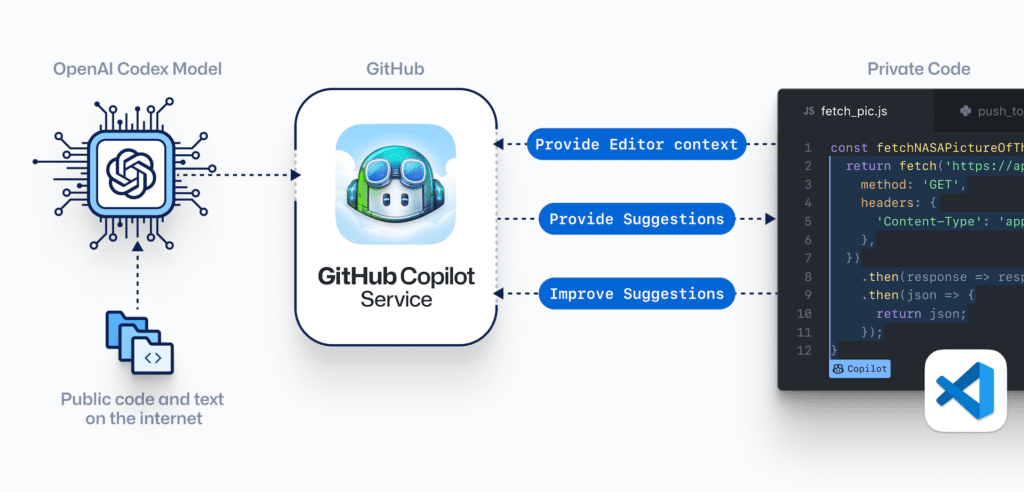
GitHub Copilot understands significantly more context than most code assistants. GitHub Copilot uses the context developers provide and synthesizes code to match.
However, co-pilot is not available on general access yet.
But there are alternatives as we see below
How do these alternatives work and what can we infer from them on the future of AI apps?
Firstly, there are tools based on training a smaller body of data such as StackOverflow. Captain Stack is a code suggestion tool. It is not a code generation tool unlike co-pilot. It uses StackOverflow to answer your code question and autocomplete the code. Thus, it automates what many of us do manually!
There are others built on top of Captain Stack such as GPT-Code-Clippy.
Second Mate is a code-generation tool using EleutherAI GPT-Neo-2.7B (via Huggingface Model Hub) for Emacs. It too is thus trained on a smaller body of data.
Then there are tools based on code search and recommendation. For example Clara-Copilot makes use of Code Grepper. So, it is a code search and recommendation solution as opposed to code generation.
What are the implications of this approach?
GPT-3 and hence co-pilot is both simple and powerful. While they are early and experimental, their power lies in the large language models that has been acquired and maintained. This is not ever likely to be cheap or free
From the above, we see that there are two options: Use a smaller dataset to train(like stack overflow) or use a code search engine for code recommendation. But these are not the same thing ie they are not code generators like co-pilot. For that you need large language models which are expensive to build and train.
Finally, open source is a red herring – it’s the model that matters and not the fact if the code is open or not
My conclusion is
- Large language models are truly disruptive in terms of their capacity to generate code
- Current alternatives are very limited and can never provide the same functionality
- Code generators based on large language models will always be expensive.
- Models trained on smaller datasets (like stack overflow) may provide some functionality but not the context and hence not the generation ability.
- The future thus tends to large language models with the assumptions that these models may be commercially more accessible in future
{kind=link}