

When we talk about innovative services or products, many startups follow a smoother model of development. This allows them to minimize the risk to be able to have improvements when collecting capital to finance themselves. Once they found the market fit, the issue will be about the growth, to achieve a balance point.
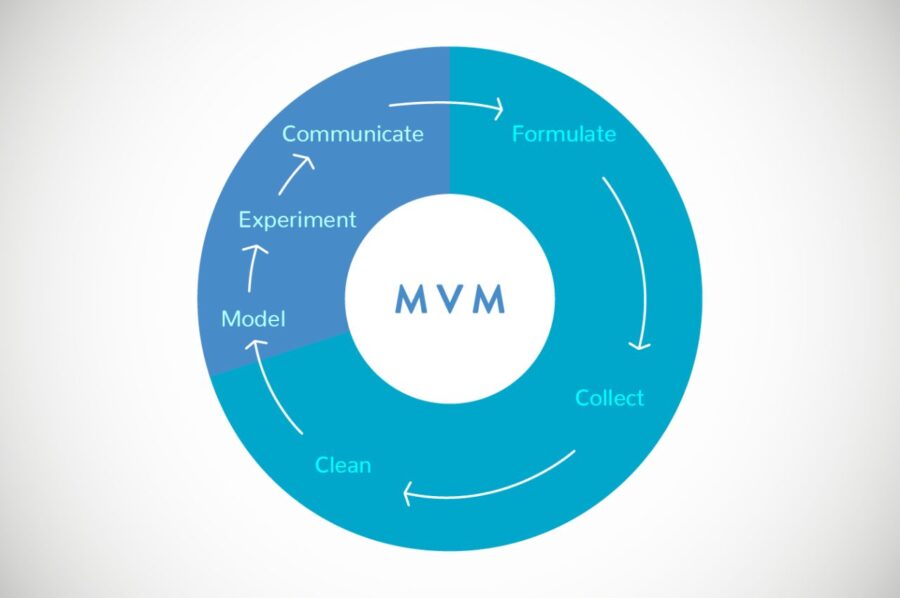
For those startups based on data (nowadays, most of them consider their data as a strategic active for the decision making), to find a model that interprets them is a difficult task. Extract/collect data, measure, model and making decisions is a common road for any startup that aims to a dynamic, changing, fluid sector of the market.
It is the data scientist or the data science team’s task to find that/ those model/s, but finding it/them (determine the modelling technique, setting parameters and adjustment) may be a very long, and sometimes, non-aligned task with the business times. For example: it does not make sense a model to “predict the results of a football match” that finds the results after the match was played. So, how startups can minimize this risk when launching a new app? Do they need so much deployment to enter the market, do they have the necessary resources? In 7Puentes we understand they do not and that is why we coined a new concept: MVM (Minimum Valuable Model).
MVM is based on the principle that data-based startups need to have affordable data science models for their financial reality but also, these models have to be acceptable in terms of accuracy. This working methodology based on minimum and effective models, minimizes the risks in the event the product does not succeed in the market and, therefore, is an obstacle less in regards to the launching.
“A data science model with 75% of accuracy, which is acceptable to guarantee the well-functioning of the app, takes 25% of the time. To escalate to a 100%, i.e., to a perfect model, exponentially increases the time used and the required investment,” explains Carlos Lizarralde, 7Puentes’ CEO.
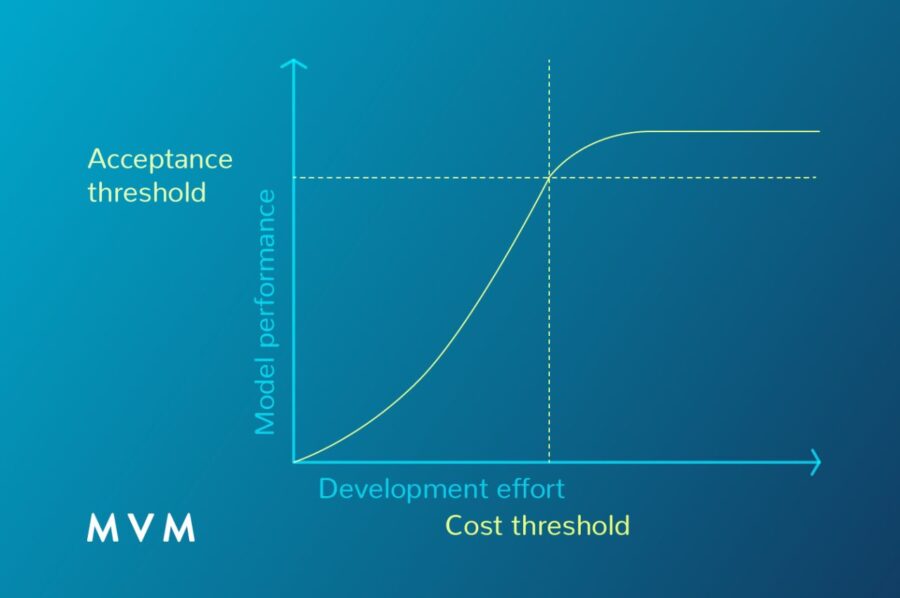
If we think a model of recommendation for an app like “Tinder”, a MVM does not need the 10 offers to be ideal, but, to have out of 10 offers an average of good offers and, maybe, a low percentage of very bad offers. It is not necessary to develop a prediction algorithm 100% effective and it is not feasible in financial terms. Every sector/project has its “good-enough”: sometimes the priority is a quick response but in other cases the covering is the focus.
To find a MVM, it is necessary a constant dialogue between the areas that define the business goals and the data scientist. It is no use the specialist working only two months with the data, since finding the MVM requires to pay attention to what data provide. Many times, the business areas require a very precise model with training data that is not enough, they are noisy or they do not adjust to the thought model. Maybe it is better to reduce the scope of the model to the portion of the data where it better works and, in the future, expand the coverage of the model when the startup has better financial resources.
More than 70% of data science project’s efforts consist on data-junk: collection and cleaning of data. And the time for modeling, experimenting and communicating results is too short. So that MVM model comes to accelerate the knowledge extraction process from a “lean” perspective.
Click here to read original version and contact the author.
{kind=link}